1 Introduction
The study of gene expression and its regulation is central to molecular biology, providing critical insights into cellular function and organismal development. A key challenge in this field is understanding how genetic information encoded in chromosomes is regulated and transcribed into mRNA, ultimately shaping gene expression (). Recent advancements in multimodal single-cell omics technologies have enabled the simultaneous profiling of chromatin accessibility and gene expression within individual cells. By integrating the paired single-cell ATAC sequencing (scATAC-seq) and single-cell RNA sequencing (scRNA-seq) data, these technologies provide promise to identify key regulatory elements including enhancers and promoters that influence gene expression in a cell-type-specific manner.
A series of studies have been proposed to investigate the relationship between scRNA-seq and scATAC-seq data using paired multi-omics information. For example, studies have focused on generating embeddings of cells based on both gene expression and chromatin accessibility data, demonstrating strong performance in cell-type discrimination (, , , , , ). Previous studies have also explored the relationship between gene expression and chromatin accessibility through the lens of transcription factor (TF) motif analysis, aiming to construct more accurate gene regulatory networks by integrating both data types (, , , , ).
However, only a limited number of studies have focused on the identification of regulatory elements that influence gene expression (, , , , , , ). Most of these methods rely on regression or predictive models to establish associations between chromatin accessibility peaks and expressed genes. While these models are useful, they often struggle to handle the inherently weak peak signals and may fail to fully detect certain important regulatory interactions between peaks and genes. Studying relationships among peaks and genes—such as peak–peak co-accessibility and gene–gene co-expression—may provide valuable information for capturing peak–gene associations more effectively. A key challenge we aim to address is how to integrate these interactions to enhance the accuracy of peak–gene relationship inference. Additionally, existing methods typically analyze peak–gene associations in an isolated manner, examining each gene independently. Such a fragmented approach fails to capture the global regulatory landscape between peaks and genes, limiting our understanding of the complex interplay within gene regulatory networks. Therefore, there is a need for a more integrative framework that captures the underlying structure of peak–gene interactions in a unified manner, enabling a comprehensive representation of regulatory influences.
In this study, we propose single-cell meta-Path based Omics EMbedding (scPOEM), a novel method that jointly embeds genes and chromatin accessibility peaks into a unified low-dimensional space. Different from existing network-based methods for integrating scATAC-seq and scRNA-seq data, such as SIMBA () and scMI (), which connect peaks and genes indirectly via cells and primarily focus on cell-to-cell variation, scPOEM focuses on peak–gene associations within a group of homogeneous cells of the same cell type, enabling a more direct and biologically meaningful representation of cis-regulatory relationships. Specifically, scPOEM generates low-dimensional representations of genes and peaks to better characterize their regulatory interactions. The method first constructs a heterogeneous network incorporating peak–peak, peak–gene, and gene–gene relationships, and then employs an improved meta-path-based approach for heterogeneous network embedding. In the resulting low-dimensional space, a peak and a gene that are closer together are considered to exhibit a stronger regulatory association. Compared to other network embedding methods, scPOEM provides more stable and interpretable cross-modal integration. In benchmarking analysis, scPOEM demonstrates superior performance in detecting experimentally validated super-enhancers and in identifying Promoter Capture HiC (PCHiC) interactions, compared to existing regression-based methods. Furthermore, by clustering genes in the low-dimensional space and examining the closest peaks corresponding to each cluster of genes, scPOEM enables the exploration of relationships between gene and peak groups, offering new biological insights in peak–gene regulatory mechanisms. Meanwhile, with real data, by applying scPOEM to memory CD4+ T cells from the HIV-infected and control samples, we reveal significant differences in peak–gene relationships for disease-associated genes, providing new insights into how chromatin accessibility and gene regulation are altered.
2 Materials and methods
2.1 Quality control and preprocessing
scPOEM uses paired scRNA-seq and scATAC-seq data as input. We adhered to the standardized QC procedures for both scRNA-seq and scATAC-seq datasets. Starting with the quality control (QC) for cells, cells with excessively low or high RNA and ATAC counts, as well as those with mitochondrial read proportions exceeding 20%, were excluded. For the feature-level filtering, we retained peaks located on “standard” chromosomes and genes with valid annotations. We also removed peaks and genes from the X, Y, and mitochondrial chromosomes, as well as those located within blacklisted genomic regions. Peaks detected in fewer than five cells and genes detected in fewer than 1% cells are also removed. The scRNA-seq data were sequentially library-size normalized, log transformed and scaled. Then 3000 highly variable genes (HVGs) were selected for downstream analysis. The scATAC-seq peak counts were subsequently transformed using TF-IDF. The Seurat (v5.1) () and Signac (v1.13) () R packages are used to process the scRNA-seq and scATAC-seq data in practice.
2.2 The scPOEM workflow
There are three main steps of scPOEM as shown in Fig. 1. After preprocessing, scPOEM first constructs peak–peak, peak–gene, and gene–gene networks, forming a joint peak–gene network. Then based on this joint network, scPOEM generates meta-paths of the scheme via random walk, using different transition matrices for each type of link. Finally, based on the training dataset derived from the meta-paths, the heterogeneous network embedding method creates embedded features for each gene and peak in the same low-dimensional space. For each gene, scPOEM calculates its distance to each peak, with the nearest peaks considered to have a potential functional relationship with the gene and influence its expression. The embedding step of scPOEM is inspired by the metapath2vec algorithm (), but differs significantly by generating meta-paths through a regulatory-based process that explores higher order relationships between peaks and genes. The details of the three steps are described in the following subsections.
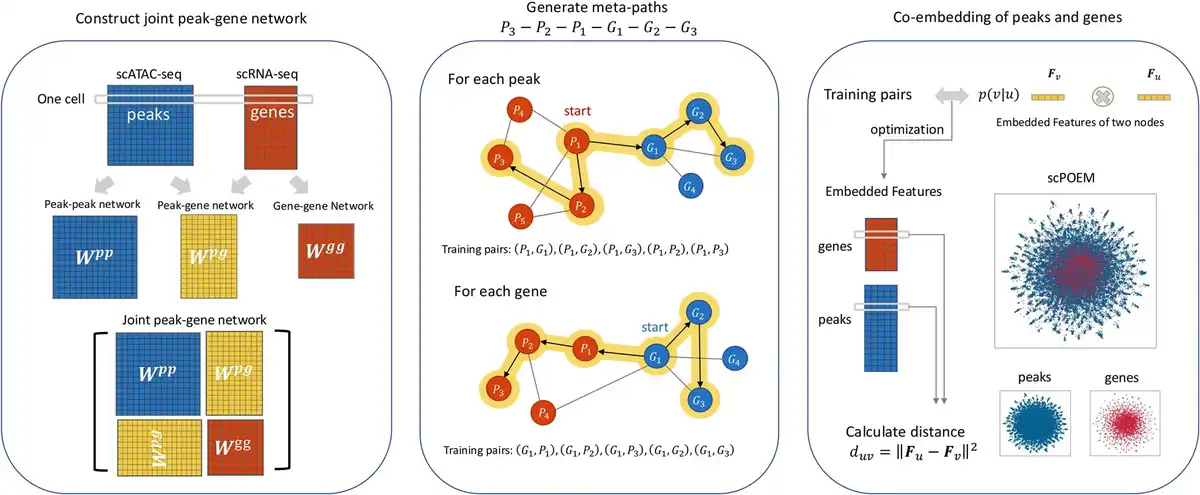
Figure 1
The scPOEM workflow. It includes constructing the joint peak–gene network, generating meta-paths through heterogeneous random walks, and co-embedding peaks and genes.
2.3 Constructing the joint network of peaks and genes
For cells, suppose is the matrix for the scATAC-seq data with peaks, and is the count matrix for the scRNA-seq data with genes. The scPOEM first builds the joint regulatory network of peaks and genes based on and , which consists of three parts—peak–peak network, peak–gene network, and gene–gene network. This joint network belongs to the heterogeneous network as its nodes include two types of entities.
2.3.1 Peak–peak network construction
Since Cicero (, ) effectively utilizes single-cell chromatin accessibility data to predict regions of the genome that are more likely to be in physical proximity in the nucleus, enabling the identification of potential enhancer-promoter pairs and the cis-regulatory architecture, we utilized this method to construct peak–peak network. The basic workflow of Cicero involves converting the count matrix into a binary matrix, performing dimensionality reduction on cells using UMAP, aggregating cells with KNN, and finally applying a graphical Lasso model to infer co-expression patterns between pairs of peaks. To focus solely on the degree of association between peaks, irrespective of directionality, we took the absolute value of all pairwise relationships and recorded the results in the matrix , which is symmetric with all diagonal entries equal to 0. The ( , )th entry of indicates the co-expression level between the th peak and the th peak.
2.3.2 Gene–gene network construction
Many methods have been proposed to construct the gene–gene regulatory network (), and we select to use the principal component regression method, since its good performance and high efficiency as shown in existing works (,). For the th gene, use to denote the th column of and use to denote the matrix of without the th column. Principal component analysis is applied to , and the first five leading principal components are maintained to construct the new feature matrix . Denote the corresponding loading matrix for these five principal components by that . Then we use the new feature matrix to regress and the estimated coefficient by the ordinary least square method is . Compute , which reflects the effects of other genes to the th gene. After are obtained, we construct whose th column is consisted by and a zero value on the th entry. is also taken the absolute value and symmetrized, and only values greater than the 95th percentile were retained to highlight the strongest associations. can be used to reflect the strength of gene–gene interactions that a large value on its ( , )th entry indicates that the th gene and th gene are highly correlated and may regulate each other.
2.3.3 Peak–gene network construction
As discussed in Section 1, learning the relationship between peaks and genes is still in an early stage, and which method provides the best performance is still an uncontained question. Therefore, instead of using only one method, we consider using three different methods, including Lasso regression (), random forest (RF) (), and XGBoost () to analyze the interactions between peaks and genes. For each method, we construct a matrix to reflect the interaction of peaks and genes and obtain three different matrices denoted by , , and . Later on, when constructing the embedding, we will use the ensemble strategy to integrate the information of three matrices together during the embedding progress. Each method constructs its via a genewise progress. For the th gene, we use peaks within the 100 kbp upstream and downstream of the gene as explanatory variables to build prediction models for the gene expression . The detailed instructions of using three methods are included in the Supplementary Material, available as supplementary data at Bioinformatics online.
2.4 Generating meta-paths
2.4.1 Meta-path scheme
The main goal of our embedding is to extracting the peak–gene relationship in the joint regulatory network. Besides the direct links between peaks and genes in the network, we emphasize that the higher order links between peaks and genes in the network may also include information. Focusing on an existing peak–gene link between the peak and the gene , denoted by , there are two potential second-order links between peak and gene:
A peak ( ) is a potential regulatory of if it co-expresses with . This path is .
is a potential regulatory of a gene ( ) if directly regulates . This path is .
Similarly, for the third-order links, we consider the path to include the potential relationship between and , and the path to include the potential relationship between and . The above relationships can be combined into one meta-path scheme . Within each meta-path, the peak is shown to related to , , , , and , which results in five node pairs in the heterogenous network and will be used as training datasets for embedding learning. Similarly, the gene is shown to be related to , , , , and , resulting in five training node pairs. Therefore, we will focus on generating samples of this meta-path scheme for each gene and peak and construct training node pairs. While higher order links beyond the third order can be incorporated in the similar manner, they provide marginal improvements by our experiments. A detailed discussion on the impact of meta-path length is provided in Supplementary Material, available as supplementary data at Bioinformatics online.
2.4.2 Construct transitions matrices
To sample meta-paths, we consider the way to sample the next node from a given node in the joint network. As there are two kinds of nodes in the network, distinct node sampling strategies should be specified. With , , , , and , we construct four transitions matrices to guide the four sampling scenarios, respectively, as follows. To begin with, for each , we clip its non-zero values at the 10th and 90th percentiles to avoid extreme values.
Sample a peak from a peak: is normalized by row to assure that each row of equal to 1, denoted by . Then is the transition matrix of peaks.
Sample a gene from a gene: Similarly, is normalized by row and denoted by . is the transition matrix of genes.
Sample a gene from a peak: , , and are normalized by row and denoted by , , and , respectively. Then we construct , which is the transition matrix from peaks to genes.
Sample a peak from a gene: , , and are normalized by row and denoted by , , and , respectively. Then we construct , which is the transition matrix from genes to peaks.
and are constructed via the ensemble strategy. We define the SampleNode function as
function
← sample_from_distribution
return
2.4.3 Training node pair construction
Algorithm 1 includes the specific way to generate meta-paths from peak and gene aspects respectively via random walks. We emphasize that each node pair is also associated with a weight of , where denotes the number of nodes between two nodes in the meta-path. The output set of training node pairs is denoted by .
Algorithm 1
Input: Transitions matrices , , and ; The number of loops ; Three empty lists , , and .
For do
Foreach peak in do
; ;
; ;
;
;
; ;
; ;
;
EndFor
Foreach gene in do
;
;
;
.
; ;
; ;
EndFor
EndFor
Output: The meta-path lists and , and the training node pair set .
2.5 Learning co-embedding of peaks and genes
Given the training node pair set , we construct d-dimensional embeddings of peaks and genes, represented as . For the th tuple in , the embeddings of and are given by the corresponding row vectors of , denoted as and , respectively. To train the embedding matrix, we maximize the product of the probability for each pair, which have a form of
where denotes the inner product of two vectors and is the vertex set that includes all genes and peaks. Since the dominant of is hard to calculate, we apply the negative sampling technique () that for each pair ( ), we randomly sample negative nodes, denoted by from the set of all peaks and genes. The final objective function to maximize can be written as
where is the sigmoid function and is the number of node pairs in . This optimization problem can be solved by block stochastic descent easily in the similar way of the meta-path2vec algorithm.
Using the low-dimensional representation , we calculated the Euclidean distance between each pair, including peaks and peaks, peaks and genes, as well as genes and genes in the unified space as . For each gene, nearby peaks at a short distance suggest potential functional relationships.
2.6 Datasets
Four groups of paired scATAC-seq and scRNA-seq datasets from three studies are used in our study. These studies were performed by different laboratories, thereby ensuring independent experimental conditions. All paired datasets are derived from the “10× Genomics Chromium Single Cell Multiome ATAC + Gene Expression” multiomics technology. Table 1 gives a summary of these datasets. The PBMC dataset was downloaded from 10× Genomics. Cell types were annotated using information from TRIPOD () with Naive CD4+ T cells selected for analysis. The BMMC dataset is obtained from GEO (GSE194122) (), and we focus on the donors of site 1 and the cell type of CD8+ T as it has the largest number of cells. The HIV datasets, obtained from GEO (GSE239916) contains memory CD4+ T cell samples from infected and uninfected donors (). We selected two representative samples: the healthy case (denoted by HC) and the early viremia-state HIV-infected case YW8 (denoted by HIV) to compare regulatory mechanisms between immunologically naive and initial viral exposure states. By applying the proposed method to the data of each condition, we can investigate the ability of our method to uncover disease-associated regulatory mechanisms.
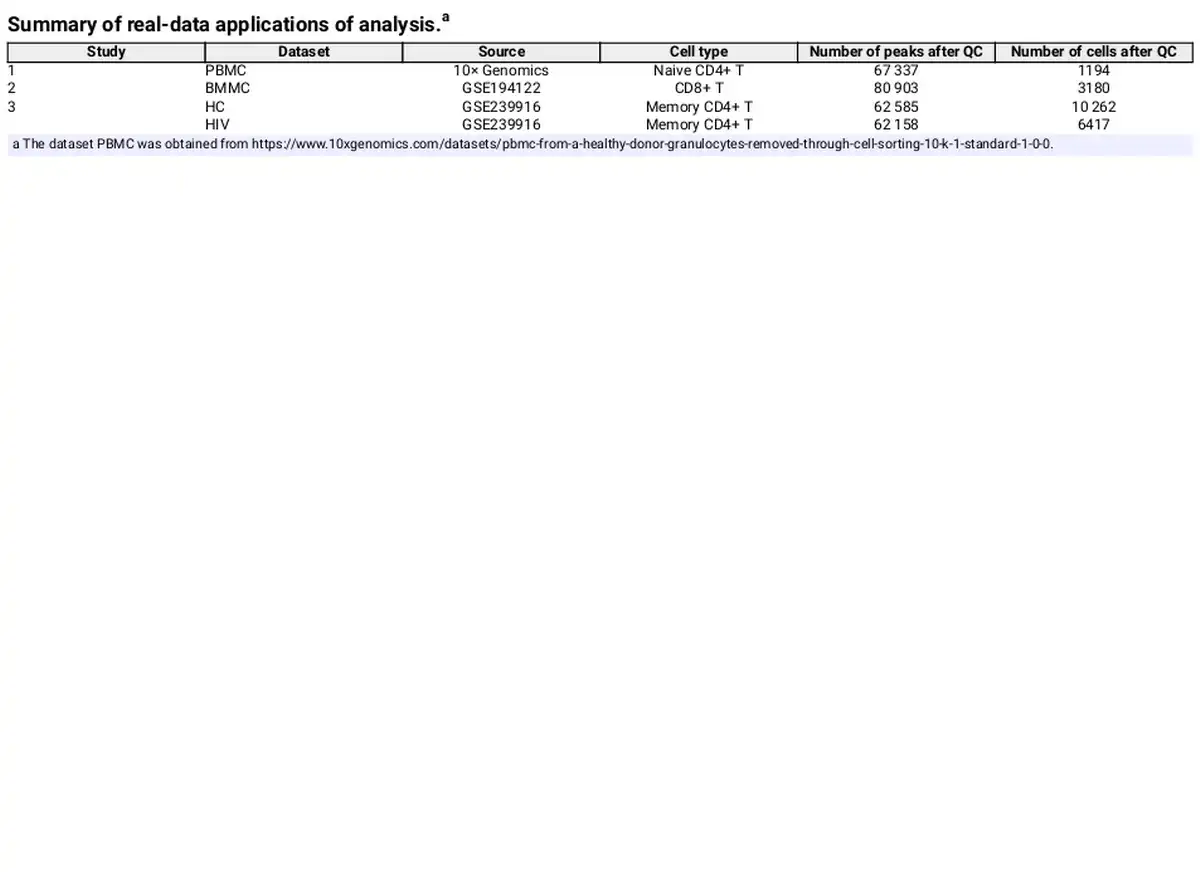
2.7 Performance evaluation
For evaluation, we constructed a = 100-dimensional embedding for each gene and peak using scPOEM for each dataset. The computing time of scPOEM for different datasets is included in the Supplementary Material, available as supplementary data at Bioinformatics online. We evaluated the overall effectiveness of scPOEM from four aspects. First, to assess its ability to identify super-enhancer-associated peaks, we utilized the SEA database () to compare scPOEM with Lasso, RF, and XGBoost in detecting peak–gene pairs within 200 kb of the gene body by precision and recall. We also examined whether peaks overlapping with super-enhancers tend to be assigned closer distances to their target genes in the latent space using boxplots. To evaluate scPOEM’s effectiveness in identifying PCHiC interactions, we analyzed a publicly available PCHiC dataset () to assess the overlapping number between the closest peak–gene pairs inferred by scPOEM and PCHiC interaction regions. Additionally, to evaluate scPOEM’s effectiveness in identifying gene groups with regulatory mechanisms, we clustered genes based on the embedded features and identified a group of closest peaks for each gene subgroup. We then applied gene enrichment analysis via EnrichR () and peak set enrichment via GREAT () to explore the potential regulatory roles within each cluster. Finally, to assess scPOEM’s ability to identify disease-associated regulatory factors, we constructed a new gene–gene network using embedded features for each of the healthy and HIV-infected datasets and employed the manifold alignment technique proposed by scTenifoldNet (, ) to detect differentially regulated genes between the two conditions. We further analyzed the regulations of the top differentially regulated genes and their closest peaks. A more detailed description of the performance evaluation is included in the Supplementary Material, available as supplementary data at Bioinformatics online. All external resources used for evaluation are independent of the four scRNA-seq and scATAC-seq datasets, ensuring the validity and robustness of our entire evaluation process.
3 Results
We applied scPOEM to four datasets and generated 100 embedding features for each peak and gene. The same parameter settings were used across all experiments: during co-embedding learning, we employed stochastic gradient descent with a batch size of 32, a learning rate of 0.1, and early stopping after 100 training epochs. In each epoch, we sampled five random meta-paths per node and drew five negative samples for each positive peak–gene pair within a meta-path. The detailed numerical values of the embedding features are provided in the Supplementary Materials, available as supplementary data at Bioinformatics online.
3.1 scPOEM provides robust co-embedding and better mixing of peaks and genes
Figure 2 displays the two-dimensional UMAP projection () of the 100 embedded features generated by scPOEM. For comparison, three popular network embedding methods—Laplacian Eigenmaps (), Structural Deep Network Embedding (SDNE) (), and DeepWalk ()—were also applied to the joint network of peaks and genes, with their results visualized using UMAP. For each dataset, it is clear that scPOEM achieves the best cross-modality integration of scATAC-seq and scRNA-seq data, resulting in a robust and improved mixing of genes and peaks that reflects their shared regulatory space. In all cases, scPOEM produced a more dispersed distribution, positioning genes between peaks to better reflect the biological organization of regulatory elements. This structure enhances the interpretability of peak–gene relationships and aids in identifying potential regulatory interactions. In contrast, Laplacian Eigenmaps tended to separate peaks and genes into distinct clusters, failing to integrate information from both modalities effectively. While SDNE and DeepWalk outperformed Laplacian Eigenmaps in cross-modal integration, their embeddings are overly compact. Most genes and peaks are densely clustered in the center, making it difficult to infer regulatory interactions.
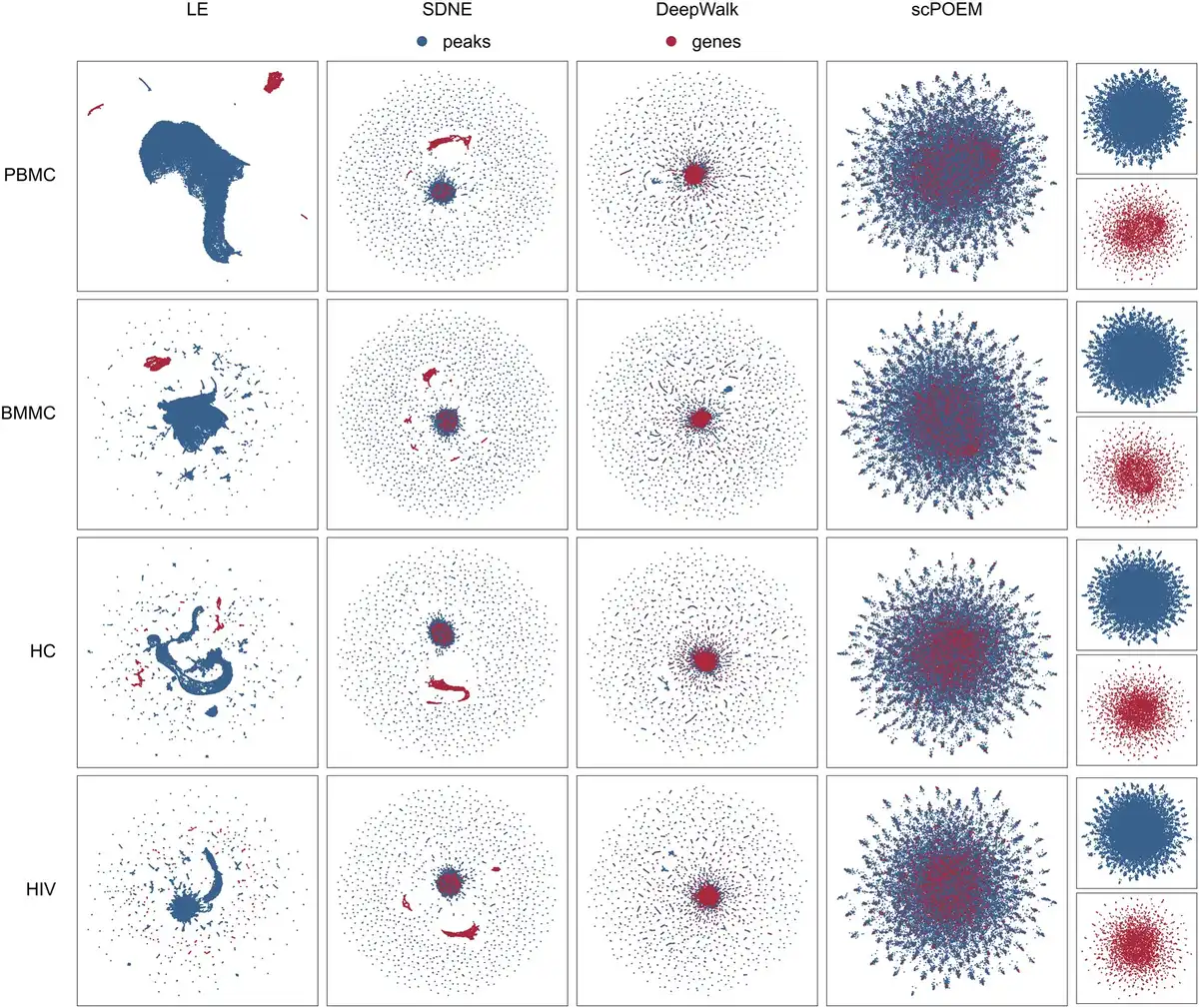
Figure 2
Two-dimensional UMAP visualization of 100 embedded features generated by Laplacian Eigenmaps, SDNE, DeepWalk, and scPOEM for four datasets.
Sensitivity analysis is conducted to assess the stability of our method in providing low-dimensional embeddings. For example, using the PBMC data, we created two random subsamples of 90% of the cells and applied the scPOEM method to each subsample. For each gene, we compared the ranks of peaks based on their distance to the gene in both subsamples via Spearman correlations. The Spearman correlations for all genes range from 0.77 to 0.81, with a median value of 0.802. These results indicate that the ranks of peaks relative to genes are stable across different data subsamples, further demonstrating that scPOEM provides robust co-embedding of peaks and genes.
3.2 scPOEM demonstrates superior performance in identifying super-enhancer regions and PCHiC interactions compared to regression methods
We investigated whether nearby peaks and genes in the embedded space exhibit more realistic regulatory information and reflect chromatin–gene relationships. We first assessed the performance of scPOEM in identifying super-enhancer regions for each gene in Fig. 3. Figure 3a shows the number of super-enhancers covered by the top peak–gene pairs detected by scPOEM, Lasso, RF, XGBoost, and random selection. scPOEM achieves overall higher precision and recall compared to Lasso, RF, and XGBoost, indicating that scPOEM effectively captures key regulatory interactions within the joint regulatory network of genes and peaks. Figure 3b presents boxplots of the distances between genes and peaks overlapping with super-enhancer regions, which are generally lower than those of peaks outside super-enhancer regions. This result suggests that scPOEM assigns closer embeddings to functionally related regulatory elements, effectively capturing underlying regulatory interactions.
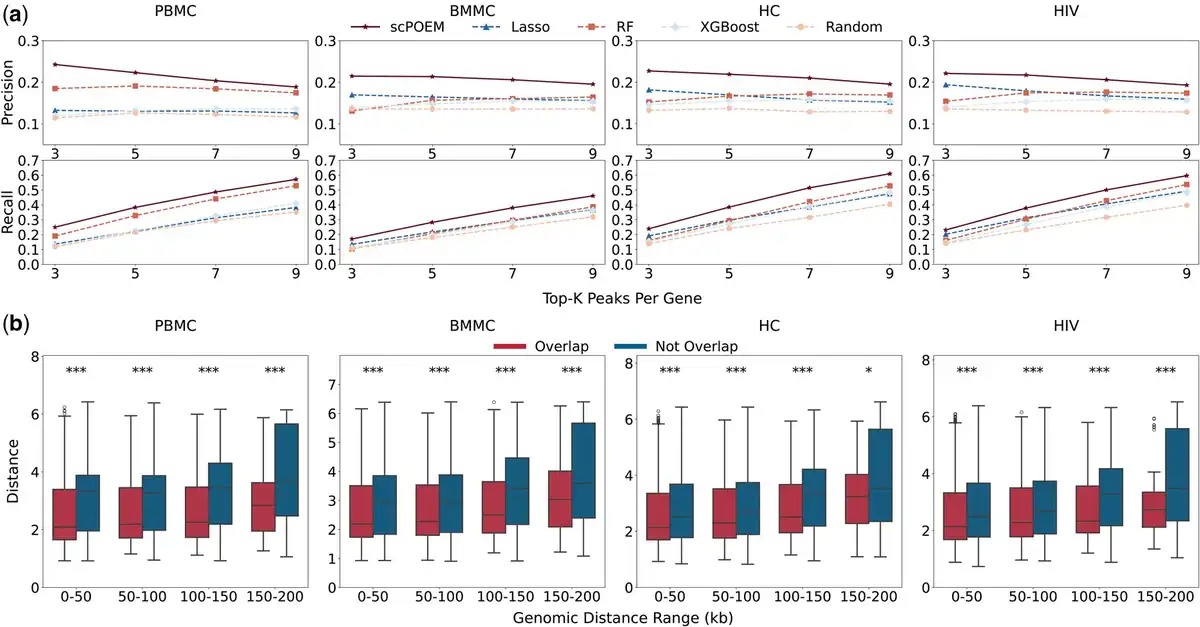
Figure 3
Performance in identifying super-enhancer regions. (a) Average precision and recall of the compared methods for detecting super-enhancer-associated peaks for each gene across four datasets. (b) Boxplots of embedded distances for peak–gene pairs within different neighborhood windows, comparing peaks overlapped and not overlapped with super-enhancer regions.
Next, we evaluated the performance of scPOEM in identifying PCHiC interactions, as shown in Fig. 4. Figure 4a displays the number of PCHiC interactions matched by the top peak–gene pairs for each method. scPOEM consistently achieves higher overlapping than other methods across different settings, demonstrating its ability to capture key regulatory interactions within the joint regulatory network of genes and peaks. Two examples are provided in Fig. 4b to illustrate the superiority of scPOEM. For the PBMC dataset, CD69 is a key regulator of T cell function, particularly in naive CD4+ T cells, where it influences differentiation and helps maintain immune homeostasis (). scPOEM assigns higher importance scores to peaks in PCHiC interaction regions than other methods for CD69. For the BMMC dataset, CD27 is a critical marker gene for CD8+ T cells, promoting their survival, facilitating memory formation, and distinguishing early stage from terminally differentiated subsets, as terminally differentiated effector CD8+ T cells often lose CD27 expression (). Similarly, scPOEM outperforms other methods in identifying PCHiC interactions for CD27.
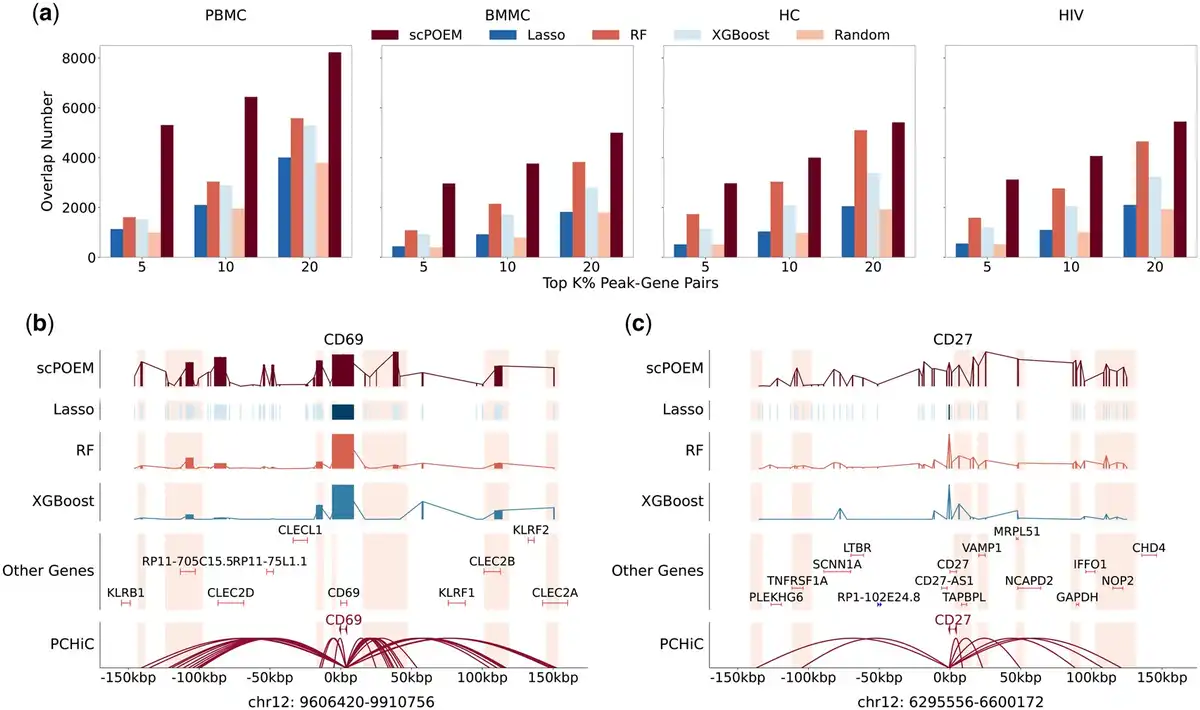
Figure 4
Performance in identifying PCHiC interactions. (a) The number of overlaps between PCHiC interactions and different percentages of top peak–gene pairs identified by scPOEM and other methods. (b–c) Examples of scPOEM interpretation for the CD69 gene in the PBMC dataset and the CD27 gene in the BMMC dataset. The curves show the importance scores of different methods across peaks in the upstream and downstream of the target gene, with highlighted regions indicating PCHiC interactions. For scPOEM, the importance score is calculated as exp(-dist), where dist is the distance between the peak and the target gene in the low-dimensional space.
By performing ablation experiments, we found that the improvement from using the ensemble strategy is modest compared to using only RF or XGBoost in scPOEM. Therefore, users may choose to use a single method to reduce computational time. More details are provided in the Supplementary Material, available as supplementary data at Bioinformatics online.
3.3 scPOEM provides consistent and enhanced group-level analysis for genes and related peaks
Using the PBMC dataset as an example, it contains 3000 HVGs and 67 337 peaks after preprocessing. We grouped genes into 100 subgroups of sizes 10–50 and assigned each subgroup a set of peaks based on the embedded features. The average number of related peaks per subgroup is 45.18. Within each subgroup, we conducted gene enrichment analysis, identifying a total of 705 distinct pathways. Figure 5a shows the number of gene subgroups associated with each pathway, revealing that most pathways are enriched in only one subgroup, indicating that scPOEM effectively groups functionally related genes together. We then performed peak enrichment for each group of peaks, first identifying enriched genes, which were then mapped to enriched pathways. As shown in Fig. 5b, the enriched genes identified by peaks largely overlap with subgroup genes. Figure 5c presents an example of subgroup #49 where ENSA, MCL1, RNF34, TBKBP1, KPNB1, and ADAMTSL4 are enriched by peaks. Notably, ENSA and RNF34 are among the top 3000 HVGs, but only ENSA is assigned to the gene group. Although RNF34 is not included in this group, our approach still successfully associates it with the relevant regulatory context. RNF34 is located in a closely related subgroup—the third nearest—highlighting our method’s sensitivity in capturing functionally connected genes beyond the HVG set.
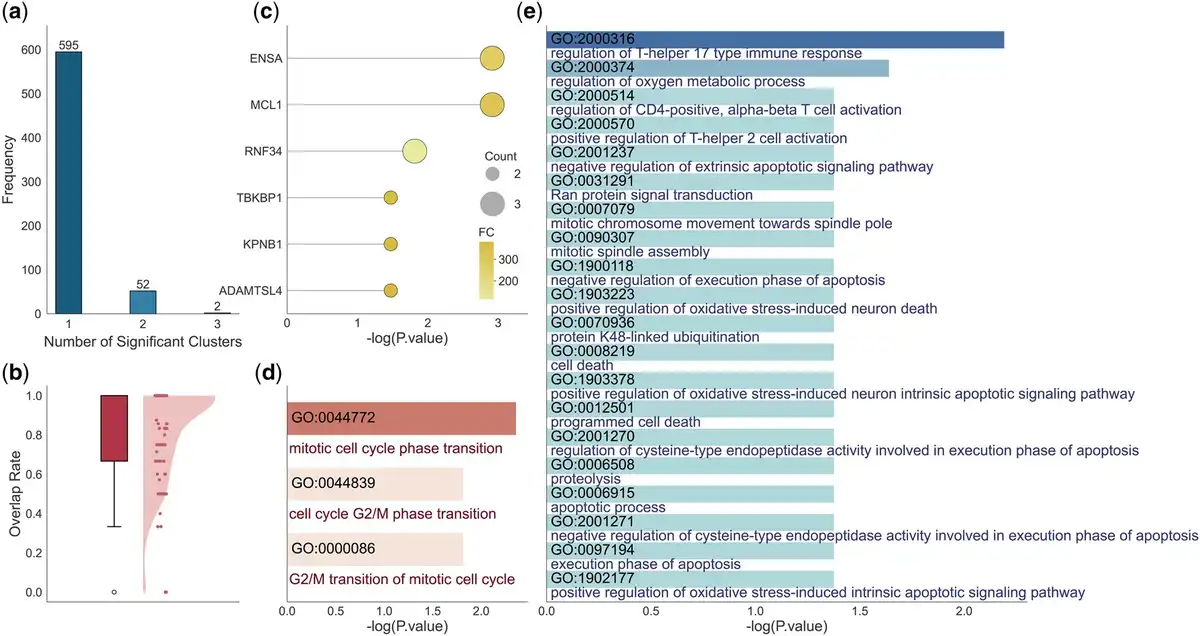
Figure 5
Enrichment results for gene and assigned peak groups in the PBMC dataset. (a) Distribution of subgroup counts related to one enriched pathway. (b) Percentage of genes enriched by peaks that are covered by the gene subgroup (considering only those within the retained HVGs). (c–e) Results for an example gene group (the #49 gene group) and its assigned peaks: (c) List of enriched genes by peaks. (d, e) Lists of enriched pathways by genes and peaks via EnrichR and GREAT, respectively.
Subgroup genes and those identified by peaks in the subgroup are functionally related and often provide complementary insights into gene functions. For example, Figure 5d and e shows the pathways identified by genes and peaks in subgroup #49. Gene enrichment highlighted key cell cycle-related pathways such as “mitotic cell cycle phase transition” (GO:0044772) and “G2/M transition of mitotic cell cycle” (GO:0000086). Similarly, peak-based enrichment revealed a broader set of functionally related pathways, including “mitotic spindle assembly” and “mitotic chromosome movement towards spindle pole,” underscoring active cell proliferation. Additionally, immune-related pathways such as “regulation of T-helper 17 type immune response” and “regulation of CD4-positive, alpha-beta T cell activation” were identified, reflecting the specific identity and functional state of naive CD4+ T cells (). Furthermore, apoptotic and stress response pathways found in the peak-based results, such as “execution phase of apoptosis” and “positive regulation of oxidative stress-induced intrinsic apoptotic signaling pathway,” align with the tightly regulated survival mechanisms in immune cells. Some enriched apoptotic pathways, including “negative regulation of cysteine-type endopeptidase activity involved in execution phase of apoptosis,” “apoptotic process,” “regulation of cysteine-type endopeptidase activity involved in execution phase of apoptosis,” “negative regulation of execution phase of apoptosis,” “negative regulation of extrinsic apoptotic signaling pathway,” and “execution phase of apoptosis” work in tandem with mitosis to maintain cellular turnover, where uncontrolled mitosis leads to proliferation, while apoptosis ensures proper cell clearance (). These findings validate the reliability of co-embedding peaks and genes and highlight the advantage of leveraging both to identify significant regulatory pathways over using genes alone. The gene and peak lists and their enrichment results for the remaining subgroups are included in the Supplementary Material, available as supplementary data at Bioinformatics online.
3.4 scPOEM reveals significant differences in peak–gene regulatory interactions between HC and HIV conditions
We applied the differential analysis described in performance evaluation to identify differentially regulated genes between HC and HIV conditions via scPOEM, as shown in Fig. 6a. NCBP3 ranked first among these genes. NCBP3 is an adapter protein that links capped RNAs (m7GpppG-capped RNA) to NCBP1/CBP80, playing a critical role in inhibiting virus growth (). Focusing on NCBP3, we selected its nearest 100 peaks in the embedded space for both conditions and conducted enrichment analysis using GREAT. The enriched genes for both conditions are shown in Fig. 6b. We found that NCBP3 is among the enriched genes in the HIV condition but not in HC, suggesting enhanced regulatory activity targeting this gene during HIV infection compared to healthy states. In terms of enriched pathways shown in Fig. 6c and d, the “integrin-mediated signaling” pathway was specifically identified in the HIV dataset but absent from the HC dataset, highlighting its critical role in HIV pathogenesis. This finding aligns with the known dependence of HIV on cell adhesion molecules for viral entry and dissemination. Specifically, integrins such as α4β7 and LFA-1 act as co-receptors for HIV-1 entry, promote virological synapse formation, and regulate immune cell trafficking that are activated during HIV infection (). These results validate scPOEM’s ability to project genes and related peaks to close locations in the co-embedding space.
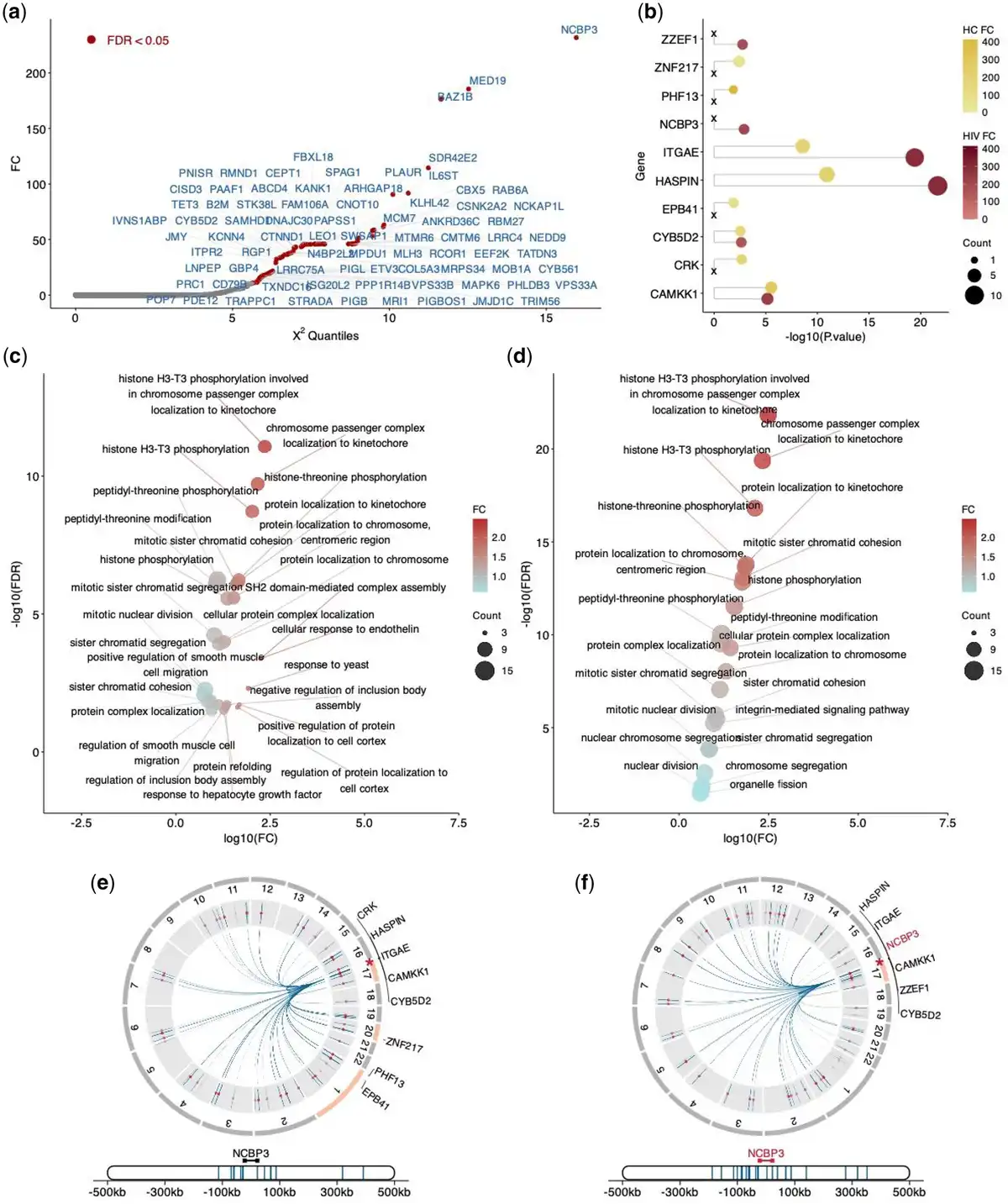
Figure 6
Differential analysis of regulatory gene networks between HC and HIV conditions. (a) Differentially regulated genes identified by scPOEM using the manifold alignment technique. (b) Enriched genes by the 100 nearest peaks of the NCBP3 gene for both conditions using GREAT. (c, d) Enriched pathways by the 100 nearest peaks of the NCBP3 genes for both conditions. (e, f) Visualization of the NCBP3 gene, its related peaks, and the enriched genes by peaks on chromatins in both conditions.
Figure 6e and f visualize NCBP3, its 100 nearest peaks, and the enriched genes associated with these peaks in each condition. These peaks may be located outside the neighborhood regions of NCBP3 or even on different chromosomes. In the HIV dataset, the nearest peaks are primarily found within the same chromatin as NCBP3, with all enriched genes residing in this chromatin. In contrast, the HC dataset shows that the enriched genes come from three different chromatins, with limited existing evidence for them, suggesting that they may arise from noise and are less biologically relevant.
Besides NCBP3, PLAUR—ranked sixth in our analysis—has been reported to have a direct association with HIV. Specifically, PLAUR inhibits HIV-1 virion release from the cell membrane and reduces viral transmission (). A detailed analysis of PLAUR is provided in the Supplementary Material, available as supplementary data at Bioinformatics online. These findings further validate the effectiveness of scPOEM in integrating scATAC-seq and scRNA-seq data, enabling accurate co-embedding of genes and peaks. Additionally, it offers a new approach to investigate gene regulation by first considering related peaks and then examining the relationship between the target gene and those enriched by these peaks. Moreover, by following a similar scheme, this differential analysis framework can be used to detect regulatory variations between different cell types.
4 Conclusion
In this study, we proposed scPOEM, a novel single-cell multi-omics embedding method that integrates scATAC-seq and scRNA-seq data to uncover regulatory relationships between chromatin accessibility peaks and gene expression. By constructing a heterogeneous network that includes peak–peak, peak–gene, and gene–gene relationships, scPOEM generated low-dimensional embeddings that effectively capture the regulatory landscape of genes and peaks. Our experimental results demonstrated that scPOEM outperformed existing methods in identifying super-enhancer-associated peaks, recovering PCHiC interactions, and conducting subgroup and differential regulatory mechanism analyses.
One key strength of scPOEM is its ability to integrate peak–peak, peak–gene, and gene–gene relationships into a unified framework, enabling the discovery of biologically meaningful patterns. For example, by leveraging the embedded features for differential analysis, scPOEM successfully identified differentially regulated genes implicated in HIV and revealed significant differences in peak–gene regulatory interactions between HC and HIV conditions. Another advantage of scPOEM is its ability to co-embed peaks and genes in the same space. This co-embedding enhances the interpretability of regulatory interactions and facilitates downstream analyses by allowing the simultaneous examination of peaks and genes. For instance, our experiments revealed significant relationships between the pathways identified by the associated gene and peak sets, demonstrating that scPOEM effectively projects functionally related elements into nearby locations in the embedding space. This capability is particularly valuable for uncovering cell-type-specific regulatory mechanisms and identifying potential therapeutic targets.
Despite its strengths, scPOEM has several limitations and areas for improvement. First, its computational complexity may increase with larger datasets. We are developing parallel computing strategies to address this challenge. Second, scPOEM is an entirely unsupervised method. Integrating labelled information may further improve the performance of scPOEM. Third, while scPOEM currently focuses on pairwise peak–gene relationships, extending the framework to model peak–gene–protein relationships and co-embed these three entities could enhance its utility further.
Acknowledgements
We thank the anonymous reviewers for their constructive comments.
References
- Arthos J, Cicala C, Martinelli E et al HIV-1 envelope protein binds to and signals through integrin α4β7, the gut mucosal homing receptor for peripheral T cells. Nat Immunol 2008;9:301–9.
- Bannister AJ, Kouzarides T. Regulation of chromatin by histone modifications. Cell Res 2011;21:381–95.
- Becht E, McInnes L, Healy J et al Dimensionality reduction for visualizing single-cell data using UMAP. Nat Biotechnol 2018;37:38–44.
- Belkin M, Niyogi P. Laplacian eigenmaps for dimensionality reduction and data representation. Neural Comput 2003;15:1373–96.
- Bravo González-Blas C, De Winter S, Hulselmans G et al SCENIC+: single-cell multiomic inference of enhancers and gene regulatory networks. Nat Methods 2023;20:1355–67.
- Breiman L. Random forests. Mach Learn 2001;45:5–32.
- Cai L, Ma X, Ma J. Integrating scRNA-seq and scATAC-seq with inter-type attention heterogeneous graph neural networks. Brief Bioinform 2024;26:bbae711.
- Cao Y, Fu L, Wu J et al Integrated analysis of multimodal single-cell data with structural similarity. Nucleic Acids Res 2022;50:e121.
- Cao Y, Zhao X, Tang S et al scButterfly: a versatile single-cell cross-modality translation method via dual-aligned variational autoencoders. Nat Commun 2024;15:2973.
- Chen C, Zhou D, Gu Y et al SEA version 3.0: a comprehensive extension and update of the super-enhancer archive. Nucleic Acids Res 2020;48:D198–203.
- Chen H, Ryu J, Vinyard ME et al SIMBA: single-cell embedding along with features. Nat Methods 2024;21:1003–13.
- Chen T, Guestrin C. Xgboost: a scalable tree boosting system. In: Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. San Francisco, USA. New York, NY, USA: ACM, 2016, 785–94.
- Cheng W, Yin C, Yu S et al scMMO-atlas: a single cell multimodal omics atlas and portal for exploring fine cell heterogeneity and cell dynamics. Nucleic Acids Res 2025;53:D1186–94.
- Cui X, Yin Q, Gao Z et al CREATE: cell-type-specific cis-regulatory element identification via discrete embedding. Nat Commun 2025;16:4607.
- Cusanovich DA, Hill AJ, Aghamirzaie D et al A single-cell atlas of in vivo mammalian chromatin accessibility. Cell 2018;174:1309–24.e18.
- de la Fuente H, Cruz-Adalia A, Martinez del Hoyo G et al The leukocyte activation receptor CD69 controls T cell differentiation through its interaction with galectin-1. Mol Cell Biol 2014;34:2479–87.
- Dong Y, Chawla NV, Swami A. “metapath2vec: scalable representation learning for heterogeneous networks. In: Proceedings of the 23rd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. Halifax, Canada. New York, NY, USA: ACM, 2017, 135–44.
- Dowling MR, Kan A, Heinzel S et al Regulatory T cells suppress effector T cell proliferation by limiting division destiny. Front Immunol 2018;9:2461.
- Gebhardt A, Habjan M, Benda C et al mRNA export through an additional cap-binding complex consisting of NCBP1 and NCBP3. Nat Commun 2015;6:8192.
- Granja JM, Corces MR, Pierce SE et al ArchR is a scalable software package for integrative single-cell chromatin accessibility analysis. Nat Genet 2021;53:403–11.
- Hao Y, Stuart T, Kowalski MH et al Dictionary learning for integrative, multimodal and scalable single-cell analysis. Nat Biotechnol 2024;42:293–304.
- Hendriks J, Gravestein LA, Tesselaar K et al CD27 is required for generation and long-term maintenance of T cell immunity. Nat Immunol 2000;1:433–40.
- Hu Y, Wan S, Luo Y et al Benchmarking algorithms for single-cell multi-omics prediction and integration. Nat Methods 2024;21:2182–94.
- Javierre BM, Burren OS, Wilder SP et al; BLUEPRINT Consortium. Lineage-specific genome architecture links enhancers and non-coding disease variants to target gene promoters. Cell 2016;167:1369–84.e19.
- Jiang Y, Harigaya Y, Zhang Z et al Nonparametric single-cell multiomic characterization of trio relationships between transcription factors, target genes, and cis-regulatory regions. Cell Syst 2022;13:737–51.e4.
- Kuleshov MV, Jones MR, Rouillard AD et al Enrichr: a comprehensive gene set enrichment analysis web server 2016 update. Nucleic Acids Res 2016;44:W90–7.
- Li H, Sun Y, Hong H et al Inferring transcription factor regulatory networks from single-cell ATAC-seq data based on graph neural networks. Nat Mach Intell 2022;4:389–400.
- Liu J, Xu S, Riffle D et al Understanding transcriptional regulatory redundancy by learnable global subset perturbations. In: The 16th Asian Conference on Machine Learning (Conference Track). Hanoi, Vietnam. Cambridge, USA: PMLR, 2024.
- Loers JU, Vermeirssen V. A single-cell multimodal view on gene regulatory network inference from transcriptomics and chromatin accessibility data. Brief Bioinform 2024;25:bbae382.
- Luecken MD, Bernard Burkhardt D, Cannoodt R et al A sandbox for prediction and integration of DNA, RNA, and proteins in single cells. In: Thirty-Fifth Conference on Neural Information Processing Systems Datasets and Benchmarks Track (Round 2). Virtual. New York, NY, USA: Curran Associates, Inc., 2021.
- McLean CY, Bristor D, Hiller M et al GREAT improves functional interpretation of cis-regulatory regions. Nat Biotechnol 2010;28:495–501.
- Mikolov T, Sutskever I, Chen K et al Distributed representations of words and phrases and their compositionality. Adv Neural Inf Process Syst 2013;26:3111–9.
- Mitra S, Malik R, Wong W et al Single-cell multi-ome regression models identify functional and disease-associated enhancers and enable chromatin potential analysis. Nat Genet 2024;56:627–36.
- Osorio D, Zhong Y, Li G et al scTenifoldNet: a machine learning workflow for constructing and comparing transcriptome-wide gene regulatory networks from single-cell data. Patterns 2020;1:100139.
- Pang H, Ouyang J, Yang Z et al Urokinase plasminogen activator surface receptor restricts HIV-1 replication by blocking virion release from the cell membrane. Proc Natl Acad Sci U S A 2023;120:e2212991120.
- Perozzi B, Al-Rfou R, Skiena S. Deepwalk: online learning of social representations. In: Proceedings of the 20th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. New York, USA. New York, NY, USA: ACM, 2014, 701–10.
- Pliner HA, Packer JS, McFaline-Figueroa JL et al Cicero predicts cis-regulatory DNA interactions from single-cell chromatin accessibility data. Mol Cell 2018;71:858–71.e8.
- Pratapa A, Jalihal AP, Law JN et al Benchmarking algorithms for gene regulatory network inference from single-cell transcriptomic data. Nat Methods 2020;17:147–54.
- Saelens W, Pushkarev O, Deplancke B. ChromatinHD connects single-cell DNA accessibility and conformation to gene expression through scale-adaptive machine learning. Nat Commun 2025;16:317.
- Singh R, Wu AP, Berger B. Granger causal inference on DAGs identifies genomic loci regulating transcription. In: International Conference on Learning Representations (ICLR). Virtual. New York, NY, USA: Curran Associates, Inc., 2022.
- Stuart T, Srivastava A, Madad S et al Single-cell chromatin state analysis with Signac. Nat Methods 2021;18:1333–41.
- Tang X, Zhang J, He Y et al Explainable multi-task learning for multi-modality biological data analysis. Nat Commun 2023;14:2546.
- Tibshirani R. Regression shrinkage and selection via the lasso. J R Stat Soc Series B Stat Methodol 1996;58:267–88.
- Topham CH, Taylor SS. Mitosis and apoptosis: how is the balance set? Curr Opin Cell Biol 2013;25:780–5.
- Wang D, Cui P, Zhu W. Structural deep network embedding. In: Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. San Francisco, USA. New York, NY, USA: ACM, 2016, 1225–34.
- Wei Y, Davenport TC, Collora JA et al Single-cell epigenetic, transcriptional, and protein profiling of latent and active HIV-1 reservoir revealed that IKZF3 promotes HIV-1 persistence. Immunity 2023;56:2584–601.e7.
- Xu J, Lu C, Jin S et al Deep learning-based cell-specific gene regulatory networks inferred from single-cell multiome data. Nucleic Acids Res 2025;53:gkaf138.
- Yang Y, Li G, Zhong Y et al scTenifoldXct: a semi-supervised method for predicting cell-cell interactions and mapping cellular communication graphs. Cell Syst 2023a;14:302–11.e4.
- Yang Y, Li G, Zhong Y et al Gene knockout inference with variational graph autoencoder learning single-cell gene regulatory networks. Nucleic Acids Res 2023b;51:6578–92.
- Yuan Q, Duren Z. Inferring gene regulatory networks from single-cell multiome data using atlas-scale external data. Nat Biotechnol 2025;43:247–57.
- Zeng P, Ma Y, Lin Z. scAWMV: an adaptively weighted multi-view learning framework for the integrative analysis of parallel scRNA-seq and scATAC-seq data. Bioinformatics 2023;39:btac739.
- Zhong Y, Cui S, Yang Y et al Controlled noise: evidence of epigenetic regulation of single-cell expression variability. Bioinformatics 2024;40:btae457.
- Zhong Y, Osorio D, Li G et al scTenifoldNet and scTenifoldKnk: a package suite for single-cell gene regulatory network construction, comparison, and perturbation analysis. Stat Theory Relat Fields 2025 (in press).