Introduction
In 2020, the outbreak of the novel coronavirus caused widespread shock worldwide. Governments implemented various measures, including stay-at-home orders, to mitigate the risks and control the situation. Meanwhile, citizens turned to social media platforms such as Twitter to express their emotions, seek information, and discuss their governments’ activities and performance. Researchers have examined how politicians and governments framed the pandemic using traditional or social media, as well as news media framing practices (; ). Additionally, scholars have studied how people and bots share and encounter disinformation (; ). However, few studies have explored citizens’ discursive practices in imposing meaning on an unknown and unprecedented situation. Specifically, there is a dearth of knowledge on how people framed the health crisis in non-democratic settings, where previous research has typically focused on political unrest (; ).
In addition, most such studies have utilized topic modeling, an unsupervised machine-learning algorithm that identifies topics, or sets of words that frequently co-occur in texts (). Although topic modeling has been widely adopted, its use in communication research, particularly in frame analysis, has been controversial (; ). Nevertheless, numerous studies have utilized topic modeling to identify frames without proper scrutiny and sensitivity. Additionally, the bulk of the literature has been conducted in mainstream languages such as English (; ; ; ).
To address the aforementioned gaps in the literature, the empirical analyses of this research focused on Persian Twitter (Iranian Twittersphere) during the initial wave of the pandemic. A corpus of 4,165,177 Persian tweets have been examined. To identify frames on Persian Twitter and compare the computational versus qualitative human-driven coding results in frame detection, I employed both a discursive approach and Latent Dirichlet Allocation (LDA), a widely used topic modeling algorithm. Through this study, two key contributions were made: First, the understanding of framing practices during the pandemic needs enhancement by providing evidence from an under-researched context, Iran. Second, the advantages and disadvantages of topic modeling with a qualitative approach were compared.
The structure of this article is as follows. First, an overview of framing theory, with a specific focus on networked framing will be provided. Networked framing examines how the public becomes gatekeepers on social media, shaping the spread of information and shaping public discourse (). I will explore how this theory can help to understand users’ meaning-making practices on social media. Additionally, LDA will be introduced and examined for its potential benefits and limitations in identifying frames. Next, the study’s methodology will be detailed and explained. Finally, I will present the research findings and discuss the study’s contribution to ongoing empirical and methodological debates.
Theoretical Background
Framing Theory: A Discursive Understanding
Despite the widespread use of framing theory, defining it remains challenging. Nevertheless, one of the most popular definitions was proposed by , who defines framing as “to select some aspects of a perceived reality and make them more salient in a communicating text, in such a way as to promote a particular problem definition, causal interpretation, moral evaluation, and/or treatment recommendation for the item described” (p. 52). This definition not only provides a basic understanding of framing but also suggests various types of frames. However, other researchers have proposed additional types of frames, such as equivalency framing, emphasis framing, and topic-specific or context-specific frames (). In this study, I adopt a discursive approach to framing.
From a discursive perspective, defined news frames as interpretive packages that use reasoning devices, including exemplars, metaphors, and visual images. At the core of an interpretive package, a frame allows communicators to organize issue discourse by selecting and excluding elements to make meaning of the issues. further explained that a frame links two concepts to make their connection apparent, endowing certain dimensions of complex issues with greater relevance. Building on these definitions, a frame as an interpretive package that clusters signifiers is conceptualized, which refers to an underlying shared signified. In semiotics, a sign comprises two parts: the signifier, which is the physical form that the sign takes, and the signified, which is the concept or idea that the sign represents ().
While and acknowledged the importance of reasoning devices and their links in framing, they do not fully consider the significance of their linkage to an underlying signified. I argue that the underlying signified is what constitutes a frame and articulates different signifiers in a coherent and meaningful structure.
Networked Framing During the COVID-19 Crisis
The emergence of social media has disrupted the traditional notion of framing, which was previously exclusive to mass media. With the rise of social media, individuals who were previously labeled as the audience () can now actively engage in producing and consuming iterative frames through social networks, challenging the assumed causality between source and receiver (). referred to this process as networked framing, which involves actors circulating information and adding their own layers of knowledge, beliefs, and experiences on the fly. Unlike static and permanent frames in mass media, networked frames, such as Twitter frames, are continuously revised, re-articulated, and re-circulated by both the masses and the elite ().
Although networked framing theory has been employed in various fields such as social movements (; ), refugees and immigration (), and political discourse (; ), it has not been widely used to study meaning-making practices on Twitter during the pandemic. In a rare study, examined the shift of networked frames among government media and the public on Weibo and Twitter during the COVID-19 pandemic. As a result, current understanding of how the public framed the COVID-19 crisis on Twitter is limited, particularly in understudied contexts like Iran. Thus, the first research question is as follows:
RQ1: What were the dominant networked frames on Persian Twitter during the COVID-19 pandemic?
Topic Modeling as a Frame Identification Method
The next academic dispute this article enters is the debate over the benefits and shortcomings of topic modeling in frame analysis. In recent years, topic modeling has emerged as a widely used method in frame analysis. Topic modeling refers to unsupervised computer algorithms that automatically identify latent structures in large volumes of text data (). In this article, I focus on LDA as one of the most popular topic modeling algorithms in communication research (). In earlier studies, researchers highlighted the benefits of topic modeling in identifying frames. LDA, for example, is able to condense a vast amount of text into a smaller set of topics. This approach also enables scholars to identify patterns that may not be apparent through manual coding alone (). However, early adopters of topic modeling tended to conflate the output of the algorithm with a frame without careful consideration (). Subsequently, scholars have cautioned that topic modeling can be misleading if not subjected to rigorous validity and reliability checks (). In fact, the term “topic” in “topic modeling” does not refer to any specific aspect of the algorithm’s functioning, but rather to the distribution of words (). LDA reduces language complexity to a simplistic assumption that words tend to co-occur, forming clusters that convey meaning. Also, the bag-of-words approach may not account for relationships between words that can alter their meaning. Thus, it is unclear to what extent the computational output of topic modeling, that is, “topics,” can be equated with the linguist concept of a “frame.”
As a result, several scholars have attempted to determine the conditions under which topic modeling works satisfactorily, particularly how manual qualitative interpretations and topic modeling can be utilized together in frame analysis. argued that content analysis should be purposefully integrated with computational methods based on the task at hand. Integrating topic modeling with other methods is highly emphasized (). suggested that topics obtained from topic modeling can be a valuable proxy for frames if certain conditions are met.
One can conclude that it is not advisable to abandon topic modeling as a means of identifying frames. Instead, further research is needed to determine the most effective ways to use this technique for this task. However, despite its potential strengths, many studies have used topic modeling without conducting necessary validity and reliability checks (; ). During the pandemic, researchers have employed this technique to analyze large text data to investigate social media frames. For example, analyzed public sentiments about COVID-19 in 10 highly affected countries during the first wave of the pandemic using LDA. However, their results were not robust, and they focused on English tweets in non-English speaking countries, which could lead to reliability and validity issues. These examples highlight the importance of continued research into the strengths and weaknesses of using topic modeling for frame analysis.
Furthermore, much of the current research on this topic has been conducted in mainstream languages such as English and German (; ; ). To contribute to this area of study, I have chosen to focus on an understudied language: Farsi. Investigating a new language can offer several benefits. First, it can help to understand how different cultural contexts can affect the results of topic modeling. Language is a culturally loaded entity, and this can impact the outcomes of probabilistic computer models. Topic modeling algorithms rely on patterns and relationships between words to identify topics. By understanding the nuances of a new language, one can improve the accuracy of these models and identify more nuanced frames. Additionally, there is an increasing trend toward multilingual topic modeling (). Incorporating a new language can enable one to conduct more comprehensive cross-lingual analyses. Therefore, the study aims to answer the following research question:
RQ2: To what extent can LDA results be compared to networked frames on Persian Twitter?
argued that the most important question is not the ability of computational methods to extract frames but rather what type of input data they are likely to succeed with, that is, the level of the accuracy of their results. In order to contribute to this point, I input three different datasets and compare the result of the LDA model on them with qualitative manual-driven coding that will be discussed in more detail in the section “Methods.” Before delving into the methodological details, Twitter in Iran is discussed briefly to provide the context of the research.
Twitter and the Pandemic in Iran
Iran is characterized as a non-democratic state, with limited access to social media platforms (; ). In particular, during the 2009 presidential election, the Iranian regime blocked Twitter in the wake of a large-scale protest against the regime known as the Green Movement. Despite the ban, Iranians continued to use Twitter through virtual private networks and proxies. Several academic studies have investigated the role of Twitter in political communication in Iran. These studies have demonstrated that Twitter serves as a political forum where dissident Iranians can challenge the regime, exchange sensitive information, and access content that would typically be censored in mainstream media ().
Despite extensive research on the management and health impacts of the COVID-19 crisis in Iran, there has been a dearth of studies on how Iranians have used social media during the pandemic. The first confirmed cases of COVID-19 were reported in Iran on February 19, 2020, and the country has since experienced multiple waves of the virus, with a high number of casualties. Existing studies on the COVID-19 crisis in Iran have mainly focused on its management and health-related issues (; ). Therefore, there is a gap in the current understanding of how Iranian citizens have interpreted and responded to the pandemic. This article aims to address this gap by examining how Iranian citizens performed networked framing practices on Persian Twitter during the initial wave of the pandemic.
Methods
Research data were gathered during the early stages of the COVID-19 crisis in Iran using the Twitter REST-API. Although the first cases of COVID-19 in Iran were officially reported on February 19, 2020, the research team suspected that the virus had spread earlier than the government acknowledged. Therefore, the data-collecting stage began a month before the first confirmed cases were reported, starting on January 21, 2020. Data collection continued until April 29, 2020, covering nearly 4 months of the pandemic’s initial wave. Tweets that contained relevant hashtags, including all variations of the Persian language hashtag for #Corona were collected. Tweets in Arabic were filtered out to eliminate any irrelevant data, as the spelling of Corona is identical in both languages. The data collection process yielded a total of 4,165,177 Persian tweets
In the subsequent stage of analysis, social network analysis has been utilized to create three distinct samples and investigate how different inputs can influence the results of the LDA model. First, I constructed a retweet (RT) network and designated it as the first sample, consisting of 2,519,915 tweets. Second, a PageRank centrality () to identify the 50 most influential users within the RT network were employed. Then the second sample was generated by collecting all tweets sent by these 50 influential users within the RT network, resulting in a total of 7,658 tweets. Finally, using the Cochran formula to calculate the appropriate sample size for a finite population, a representative subset of sample 2 was selected. As a result, 5,056 tweets (with a confidence level of 99%) were identified and designated this subset as sample 3. Although I used all three samples for the computational analysis phase, the qualitative analysis was only conducted on sample 3.
Three coders coded sample 3 in three consecutive rounds. The first two steps were inductive, and the final round was deductive to quantify codes across all sample tweets. In the final step, they identified 16 networked frames, including 71 sub-frames. LdaModel algorithm in Python’s Gensim library, which is a powerful tool for processing plain texts and applying unsupervised machine-learning algorithms (), was employed to conduct LDA on all samples after initial rounds of pre-processing. The LDA output was then checked by human coders, as it is detailed in the section “Findings.” The comprehensive information about human-driven coding and the LDA model, including the steps of choosing the best K-value, is presented in Appendix 1.
Findings
Networked Frames in Persian Twitter During the COVID-19 Pandemic
Figure 1 displays the networked frames, along with the proportion of each frame in sample 3.
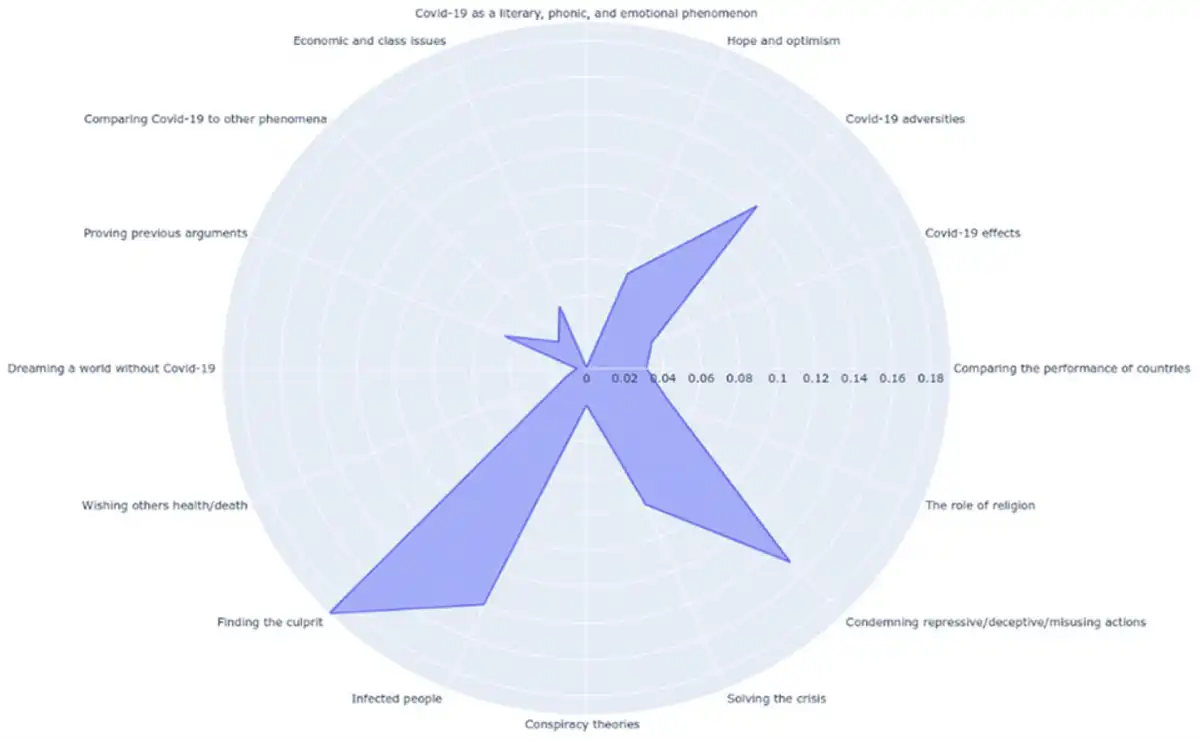
Figure 1
The frequency of networked frames in sample 3, resulting from human-driven coding.
The findings reveal that the most common networked frame in the qualitative sample is “Finding the culprit (FC),” which comprises 18% of sample. This frame revolves around determining who is responsible for the global spread of COVID-19, with a particular focus on Iran’s situation. The FC frame is inherently political, and Iranians employ it to critique various discursive identities that they deem accountable for the emergence and transmission of the virus. In this context, “identity” refers to a subject’s position within a discursive structure, as defined by , p. 43) who posit that identity is formed through chains of equivalence.
Within foreign countries, users paid significant attention to China as the country where coronavirus originated. Anti-Chinese sentiments on Persian Twitter also could have another reason. Users believe that Iran’s regime makes the country more and more isolated in the world through its hostile foreign policy. As a result, the regime has to strengthen its relations with two anti-West superpowers, China and Russia. In the views of Iranian users, China and Russia are two authoritarian regimes that help Iran’s regime to suppress Iranian citizens. In this sense, their negative sentiments against China are about something more than just China’s role in originating the virus. As a result, China became a nodal point where discursive struggles between pro- and anti-regime users were shaped (see Appendix 2, Tweet 1). Pro-regime users, in response to anti-regime criticisms of China, highlighted the shortage of medical material and the worse situation in Western countries (see Appendix 2, Tweet 2 and 3).
Concentrating on Iran, users mainly criticized the regime’s management and performance in controlling the crisis. They accused the regime of hiding the actual number of casualties. They also argued that the regime did not disclose the occurrence of the virus in real time due to its political interests. In particular, they claimed that the Iranian state’s inability to combat the virus and provide the necessary medical care was the main reason for the escalation of the crisis: “There are no masks, no disinfectants, no gloves. The IRIB is hiding the real numbers. The state has refused to quarantine cities. The number of victims is very high.”
Condemning repressive/deceptive/misusing actions (RDM) followed the FC closely as it comprised 15% of the sample. Making this frame salient, users denounced the actions of different discursive identities in misusing the situation to benefit their own needs. The discursive identities in RDM vary from hoarders to the state’s authorities. When it comes to the state, this frame overlaps with FC to a great extent: “Who is responsible? Why did IRGC collect most of the masks? The price of masks and sanitizers has raised significantly, and jobbers, who are mainly supported by the state, are hoarding the health necessities.”
Another prominent networked frame is “infected people (IP).” The exchange of news and statistics was the focus of this frame. Thus, this frame has an ambient character: “Breaking! Unconfirmed news shows more than 1,000 people infected with #coronavirus.”. On the collective level, users drew attention to the situation in other countries and Iran: “Today was the darkest day of #coronavirus in the world. The record of IP was broken. We are all facing even darker days ahead.”
At the individual level, influential users discussed the infection of public figures, such as politicians and celebrities. IP appeared along with RDM when users discussed the news about the infection of Iranian authorities. They expressed doubts about the trustworthiness of such news and claimed that the authorities were liars. They also added their personal feelings about the unequal distribution of medicines and medical supplies between the authorities and the ordinary population to the tweets tagged in this frame.
To conclude, the prevalent frames observed in the tweets from Iranian users during the COVID-19 crisis were critical narratives focused on the Iranian state’s response to the crisis, which included personal stories and affective messages mixed with news and information. While there was some attention paid to the global situation, particularly with regard to China’s role in the pandemic, it was not a major focus. The frames of “COVID-19 adversities,” “Solving the crisis,” and “Hope and optimism” were also observed. These frames were marked by discursive struggles between pro- and anti-regime users. Pro-regime users often emphasized religious and spiritual approaches, including traditional medicine, in their tweets, whereas anti-regime users emphasized the role of science in solving the crisis.
Gauging Networked Frames by LDA
In this section, I aim to answer RQ2 by presenting the results of LDA topic modeling on each sample. Table 1 is designed based on the approach. More detail is presented in Appendix 3.
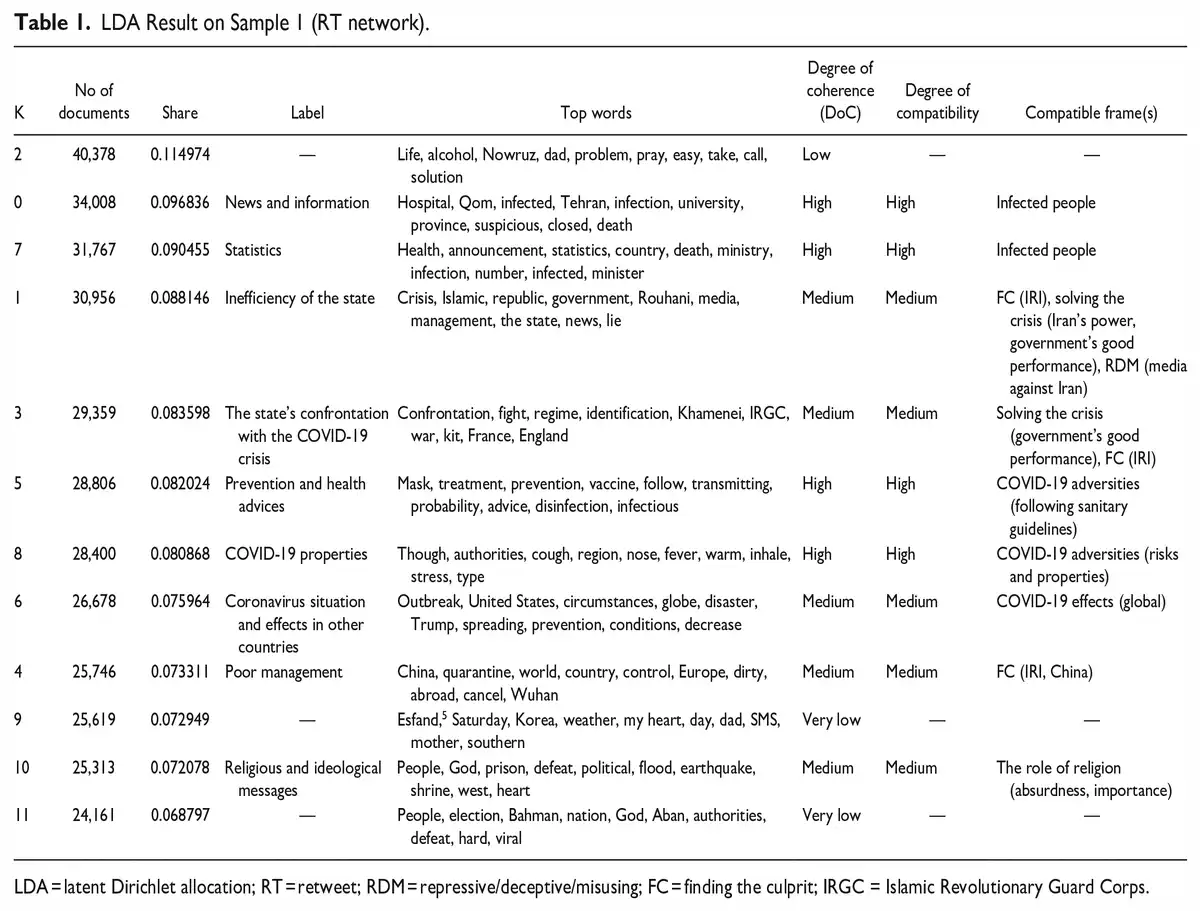
Table 1 shows despite the researchers’ best efforts to provide meaningful and reliable labels for topics through qualitative interpretation, certain topics cannot be appropriately labeled due to their incongruity, namely topics 2, 9, and 11. Additionally, LDA sometimes classified tweets with the same discursive practices, rather than frames. For instance, topic 2 pertains to users’ sarcasm and criticism, often in the form of jokes and humorous tweets. However, these tweets criticize different targets such as the state, religious figures and beliefs, and people, including the users themselves, and thus contain different networked frames or sub-frames, such as FC (IRI, People, religious figures), and the role of religion (absurdness). Although LDA recognized the underlying discursive practice (i.e., sarcasm) was the same, it failed to identify the varying targets of sarcastic tweets.
Further analyses indicate that LDA generally provides more straightforward and distinct themes, with even coherent topics having general labels that offer a primary understanding of the content but not a precise representation. As demonstrated in Table 1, LDA performs better on lexical meanings rather than compositional semantics. Specifically, LDA’s classification of tweets that contain simpler and one-dimensional information, such as health instructions (including COVID-19 properties), was more satisfactory. Such messages typically do not contain hidden political or cultural meanings, allowing LDA to classify them within meaningful boundaries successfully (topics 5 and 8).
Conversely, topics with compositional meanings were found to be less coherent and compatible with single and exclusive frames. For example, Topic 1 contains numerous tweets discussing the regime's inefficiency in controlling the crisis, with many tweets containing political and social connotations. Users were divided into two main camps, defending and challenging the regime, and LDA was unable to classify these tweets into two different topics since similar words were used to form their messages. However, human coders found more nuanced frames describing users’ struggle over the regime’s performance.
Furthermore, different levels of DoC demonstrate that there were tweets deviating from the main theme in all topics, even in topics with a high level of coherence. However, a higher DoC increases the likelihood of finding a representative label and an equivalent networked frame for a topic. In the RT network, all topics with a DoC higher than the “low” level have an analogous networked frame. Additionally, while coherent topics may shape some different frames from the identified networked frames, they did not in this case. All coherent topics in this sample equated to some networked frames and did not produce new ones.
The conducted qualitative interpretations also demonstrate that the majority of topics overlap, indicating that the same signifying chains are present in different topics, for example, topics 1, 2, 3, and 4. It is possible for a theme to be prevalent in a topic, but there are other less prominent themes shared across several topics. It also happens in human-driven coding. However, the conducted analyses confirmed that the intensity of overlapped topics is higher in LDA results. For instance, topics 0 and 7, or 5 and 8 are highly identical, and it makes sense to treat them as a single topic. LDA failed to understand that. In addition, the most prevalent qualitative frames could be found in all LDA topics, for example, FC and IP. This shows that LDA is a good technique for finding the most dominant themes, at the cost of missing less prominent ones.
Tables 2 and 3, which are presented in Appendix 3, reveal some information about how LDA works on the next samples. Since these tables are lengthy and contain more or less the same information as Table 1, they are presented and discussed in a separate Appendix. In general, the results revealed that the number of topics with lower DoC is higher in samples 2 and 3. This means that LDA works better on the bigger sample in this inquiry. It could happen because the model has more instances to analyze in bigger samples, so the accuracy increases. More discussions can be found in Appendix 3.
Discussion
This article makes a dual contribution. First, I investigate networked framing practices on Persian Twitter during the pandemic, which has been relatively neglected in the existing literature. Secondly, I aim to contribute to the ongoing discussion about the adaptation of computational methods in communication research. Additionally, since the existing literature primarily focuses on English and other mainstream languages, Persian Twitter is concentrated upon to address this gap.
The study’s results indicate that Iranian users primarily framed the COVID-19 crisis in political ways. The most dominant frames are loaded with political discussions. Frames associated with health-related issues remained less significant in comparison. This finding is consistent with the existing literature, which highlights how individuals and politicians may strategically use crisis-related meanings to further their political interests even during a global pandemic (; ). Furthermore, the dominant networked frames on Persian Twitter showed similarities to frames in other contexts, for example, in the United States. Furthermore, this study also contributes to the ongoing discussion about the reliability of computational methods in communication research. Specifically, the findings illustrate the limitations of equating individual LDA topics to networked frames. While LDA provides some insight by categorizing tweets into broad topics, it cannot produce well-defined frames with clear boundaries. Frames are more than just raw LDA topics. Results support previous studies that challenge the idea of treating LDA topics as frames (). As noted by other scholars (), there is always a gap between LDA topics and grounded frames. Currently, there is no standardized statistical method to measure this distance. Therefore, human interpretation is essential in determining the degree to which LDA outputs align with networked frames. This underscores the importance of caution and critical evaluation when working with computational results, as previous studies have warned (; ).
This study reinforces previous research that suggests computational methods are more effective with straightforward and general concepts (; ). In all cases, LDA produced such topics. Additionally, the study findings indicate that LDA produces more reliable results when analyzing the RT network, which is a larger sample. Surprisingly, LDA’s performance on smaller and more coherent samples was poorer, contradicting the expectations. also asserted that topic model outputs are not highly reliable, even with more targeted datasets. While they used datasets from different sources, I used samples from the same dataset to evaluate automated results. Nevertheless, the findings demonstrate that LDA performs better on larger datasets that are logically less targeted (; ; ).
While the primary focus was to compare LDA output with qualitative interpretation, this study also contributed to the understanding of applying computational methods to less dominant languages. Findings suggest that LDA’s performance in Farsi is slightly weaker than in other prominent languages like English (; ). This is likely due to the limited availability of computational tools and resources, such as software packages and dictionaries, for Farsi. For instance, while used linguistic inquiry and word count (LIWC) software to evaluate their results, I was unable to do the same for Farsi due to the lack of an appropriate dictionary (; ).
Another challenge is the absence of a dictionary for tokenization or lemmatization in Farsi, which can affect the efficiency of computational techniques. For example, Farsi has separate words that form a single token, like “ayt allh” (Ayat Allah: a term used for high-profile clergies). Without proper tokenization, the algorithm would classify them as two separate tokens, ayt and allh, when they are actually one token. Although there was a lack of the necessary tools to test the impact of specific steps on the results, I acknowledge that there may be some unknown effects. Therefore, it is crucial to develop such tools for non-mainstream languages, particularly given the increasing interest in multilingual topic modeling. Failure to create such resources will result in a decline in research on non-mainstream languages like Farsi, potentially limiting the understanding of the effectiveness of computational methods more broadly.
In light of these facts, I contend that additional research on languages such as Farsi is imperative for a comprehensive understanding of the opportunities and challenges associated with automated text analysis beyond widely used languages. Additionally, it is essential to acknowledge that the decision-making process during LDA implementation can significantly impact the outcomes. For example, the choice of the algorithmic package employed can have a bearing on the results, and selecting the appropriate K-value is also a critical decision. While I attempted to identify the most meaningful K-values, the sensitivity of LDA to such choices underscores the need for replication and further studies using diverse techniques. Consequently, conducting such research would enable a better assessment of the impact of different decisions on the outcomes.
Declaration of Conflicting Interests The author declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This project has received funding from the European Research Council (ERC) under the European Union’s Horizon 2020 research and innovation programme (grant agreement No 101029945.) This paper reflects only the authors’ views; the European Research Council Executive Agency is not responsible for any use that may be made of the information it contains.
Supplemental Material Supplemental material for this article is available online.
1. Throughout the rest of the article, when referring to the COVID-19 crisis and related terms such as pandemic, I specifically mean the first wave of the crisis.
2. The RT network is a directed graph G. The nodes are Twitter users and the edges are RT links between users. An edge is directed from user A, who posts a tweet, to user B, who retweets it.
3. To summarize, lexical semantics pertains to the meaning assigned to individual words in a text and the disambiguation of those words through contextualization (). Compositional semantics, on the other hand, deals with how words combine to create larger meanings ().
4. The LIWC is a software program that utilizes a dictionary comprising grammatical, psychological, and content-related word categories.
5. Aban and Esfand are the names of some months in Persian calendar.
References
- Azadi P., Mesgaran M. B. (2021). The clash of ideologies on Persian Twitter (Issue 10). University of Stanford.
- Bennett W. L., Pfetsch B. (2018). Rethinking political communication in a time of disrupted public spheres. Journal of Communication, 68(2), 243–253. https://doi.org/10.1093/joc/jqx017
- Blei D. M., Lafferty J. D. (2007). A correlated topic model of Science. The Annals of Applied Statistics, 1(1), 17–35. https://doi.org/10.1214/07-AOAS114
- Blei D. M., Ng A. Y., Jordan M. I. (2003). Latent dirichlet allocation. The Journal of Machine Learning Research, 3, 993–1022.
- Bruns A., Schmidt J.-H. (2011). Produsage: A closer look at continuing developments. New Review of Hypermedia and Multimedia, 17(1), 3–7. https://doi.org/10.1080/13614568.2011.563626
- Burggraaff C., Trilling D. (2020). Through a different gate: An automated content analysis of how online news and print news differ. Journalism, 21(1), 112–129. https://doi.org/10.1177/1464884917716699
- Burscher B., Odijk D., Vliegenthart R., de Rijke M., de Vreese C. H. (2014). Teaching the computer to code frames in news: Comparing two supervised machine learning approaches to frame analysis. Communication Methods and Measures, 8(3), 190–206. https://doi.org/10.1080/19312458.2014.937527
- Carrabine E. (2020). Structuralism. In Atkinson P. A., Delamont S., Williams R. A., Cernat A., Sakshaug J. (Eds.), SAGE research methods foundations. SAGE Publications Ltd. https://doi.org/10.4135/9781526421036759970
- Chen Y., Peng Z., Kim S.-H., Choi C. W. (2023). What we can do and cannot do with topic modeling: A systematic review. Communication Methods and Measures, 17(2), 111–130. https://doi.org/10.1080/19312458.2023.2167965
- Dada S., Ashworth H. C., Bewa M. J., Dhatt R. (2021). Words matter: Political and gender analysis of speeches made by heads of government during the COVID-19 pandemic. BMJ Global Health, 6(1), e003910. https://doi.org/10.1136/bmjgh-2020-003910
- De Grove F., Boghe K., De Marez L. (2020). (What) can journalism studies learn from supervised machine learning? Journalism Studies, 21(7), 912–927. https://doi.org/10.1080/1461670X.2020.1743737
- De Vreese C. H. (2005). News framing: Theory and typology. Information Design Journal, 13(1), 51–62. https://doi.org/10.1075/idjdd.13.1.06vre
- DiMaggio P., Nag M., Blei D. (2013). Exploiting affinities between topic modeling and the sociological perspective on culture: Application to newspaper coverage of U.S. government arts funding. Poetics, 41(6), 570–606. https://doi.org/10.1016/j.poetic.2013.08.004
- Duan Z., Li J., Lukito J., Yang K.-C., Chen F., Shah D. V., Yang S. (2022). Algorithmic agents in the hybrid media system: Social bots, selective amplification, and Partisan news about COVID-19. Human Communication Research, 48(3), 516–542. https://doi.org/10.1093/hcr/hqac012
- Easley D., Kleinberg J. (2010). Networks, crowds, and markets. Cambridge University Press. https://doi.org/10.1017/CBO9780511761942
- Entman R. M. (1993). Framing: Toward clarification of a fractured paradigm. Journal of Communication, 43(4), 51–58. https://doi.org/10.1111/j.1460-2466.1993.tb01304.x
- Gamson W. A., Modigliani A. (1989). Media discourse and public opinion on nuclear power: A constructionist approach. American Journal of Sociology, 95(1), 1–37. https://doi.org/10.1086/229213
- Grimmer J., Stewart B. M. (2013). Text as data: The promise and pitfalls of automatic content analysis methods for political texts. Political Analysis, 21(3), 267–297. https://doi.org/10.1093/pan/mps028
- Huang B., Carley K. M. (2020). Disinformation and misinformation on Twitter during the novel coronavirus outbreak. arXiv. arXiv:2006.04278. http://arxiv.org/abs/2006.04278
- Jelodar H., Wang Y., Yuan C., Feng X., Jiang X., Li Y., Zhao L. (2019). Latent Dirichlet allocation (LDA) and topic modeling: Models, applications, a survey. Multimedia Tools and Applications, 78(11), 15169–15211. https://doi.org/10.1007/s11042-018-6894-4
- Jiang M., Leeman R. W., Fu K. (2016). Networked framing: Chinese microbloggers’ framing of the political discourse at the 2012 democratic national convention. Communication Reports, 29(2), 87–99. https://doi.org/10.1080/08934215.2015.1098715
- Johnson K. (2007). An overview of lexical semantics. Philosophy Compass, 3(1), 119–134. https://doi.org/10.1111/j.1747-9991.2007.00101.x
- Jørgensen M. W., Phillips L. J. (2002). Discourse analysis as theory and method. Sage.
- Kausar M. A., Soosaimanickam A., Nasar M. (2021). Public sentiment analysis on Twitter data during COVID-19 outbreak. International Journal of Advanced Computer Science and Applications, 12(2), 415–422. https://doi.org/10.14569/IJACSA.2021.0120252
- Kermani H., Tafreshi A. (2022). Walking with bourdieu into Twitter communities: An analysis of networked publics struggling on power in Iranian Twittersphere. Information, Communication & Society, 26(8), 1653–1674. https://doi.org/10.1080/1369118X.2021.2021267
- Krishnatray P., Shrivastava S. (2021). Coronavirus pandemic: How national leaders framed their speeches to fellow citizens. Asia Pacific Media Educator, 31(2), 195–211. https://doi.org/10.1177/1326365X211048589
- Lind F., Eberl J.-M., Eisele O., Heidenreich T., Galyga S., Boomgaarden H. G. (2022). Building the bridge: Topic modeling for comparative research. Communication Methods and Measures, 16(2), 96–114. https://doi.org/10.1080/19312458.2021.1965973
- Maier D., Waldherr A., Miltner P., Wiedemann G., Niekler A., Keinert A., Pfetsch B., Heyer G., Reber U., Häussler T., Schmid-Petri H., Adam S. (2018). Applying LDA topic modeling in communication research: Toward a valid and reliable methodology. Communication Methods and Measures, 12(2–3), 93–118. https://doi.org/10.1080/19312458.2018.1430754
- Meraz S., Papacharissi Z. (2013). Networked gatekeeping and networked framing on #Egypt. The International Journal of Press/Politics, 18(2), 138–166. https://doi.org/10.1177/1940161212474472
- Nelson L. K., Burk D., Knudsen M., McCall L. (2021). The future of coding: A comparison of hand-coding and three types of computer-assisted text analysis methods. Sociological Methods & Research, 50(1), 202–237. https://doi.org/10.1177/0049124118769114
- Nicholls T., Culpepper P. D. (2020). Computational identification of media frames: Strengths, weaknesses, and opportunities. Political Communication, 38(2), 159–181. https://doi.org/10.1080/10584609.2020.1812777
- Nisbet M. C. (2009). Communicating climate change: Why frames matter for public engagement. Environment: Science and Policy for Sustainable Development, 51(2), 12–23. https://doi.org/10.3200/ENVT.51.2.12-23
- Pelletier F. J. (1994). The principle of semantic compositionality. Topoi, 13(1), 11–24. https://doi.org/10.1007/BF00763644
- Pöyhtäri R., Nelimarkka M., Nikunen K., Ojala M., Pantti M., Pääkkönen J. (2021). Refugee debate and networked framing in the hybrid media environment. International Communication Gazette, 83(1), 81–102. https://doi.org/10.1177/1748048519883520
- Rassouli M., Ashrafizadeh H., Shirinabadi Farahani A., Akbari M. E. (2020). COVID-19 management in Iran as one of the most affected countries in the world: Advantages and weaknesses. Frontiers in Public Health, 8, 510. https://doi.org/10.3389/fpubh.2020.00510
- Rodriguez M. Y., Storer H. (2020). A computational social science perspective on qualitative data exploration: Using topic models for the descriptive analysis of social media data. Journal of Technology in Human Services, 38(1), 54–86. https://doi.org/10.1080/15228835.2019.1616350
- Spector B. (2020). Even in a global pandemic, there’s no such thing as a crisis. Leadership, 16(3), 303–313. https://doi.org/10.1177/1742715020927111
- Tahamtan I., Potnis D., Mohammadi E., Miller L. E., Singh V. (2021). Framing of and attention to COVID-19 on Twitter: Thematic analysis of hashtags. Journal of Medical Internet Research, 23(9), e30800. https://doi.org/10.2196/30800
- Takian A., Aarabi S. S., Semnani F., Rayati Damavandi A. (2022). Preparedness for future pandemics: Lessons learned from the COVID-19 pandemic in Iran. International Journal of Public Health, 67, 1605094. https://doi.org/10.3389/ijph.2022.1605094
- Welles B. F., Jackson S. J. (2019). The battle for #Baltimore: Networked counterpublics and the contested framing of urban unrest. International Journal of Communication, 13, 1699–1719.
- Xu Y., Yu J., Löffelholz M. (2022). Portraying the pandemic: Analysis of textual-visual frames in German news coverage of COVID-19 on Twitter. Journalism Practice, 1–21. https://doi.org/10.1080/17512786.2022.2058063
- Yang G., Pickard V. (2017). Media activism in the digital age. Taylor and Francis.
- Ylä-Anttila T., Eranti V., Kukkonen A. (2022). Topic modeling for frame analysis: A study of media debates on climate change in India and USA. Global Media and Communication, 18(1), 91–112. https://doi.org/10.1177/17427665211023984
- Zhao X., Wang X. (2023). Dynamics of networked framing: Automated frame analysis of government media and the public on Weibo with pandemic big data. Journalism & Mass Communication Quarterly, 100(1), 100–122. https://doi.org/10.1177/10776990211072508