1 Introduction
The popularity of metagenomics for sequencing multiple organisms from clinical samples has generated increased interest in strategies to enrich metagenomic libraries for organisms of interest, both to reduce per-sample cost and to improve sensitivity. Targeted enrichment by hybrid capture, also called ‘targeted sequencing’ or ‘bait capture’ is an increasingly popular method that involves the hybridization of the metagenomic library with a potentially large panel of oligonucleotide probes, followed by amplification of the probe-bound sequences to 100– above the metagenomic background. Targeted enrichment has been shown to be unbiased at probe-target divergence of up to 20% (), providing a convenient approach for detecting and sequencing even highly diverse pathogens such hepatitis C virus (, ), and HIV (, ), as well as for analysis of genetic variation in infection () and for molecular profiling of cell-free tumour DNA ().
A key feature of targeted enrichment is that the oligonucleotide panel can be customized to include organisms or genes of interest, forming an explicit set of hypotheses against which results can be assessed. This is in contrast with shotgun metagenomic sequencing, where the entire nucleic acid extract is sequenced, and expert judgement must be made about the potential clinical significance of every identified organism.
Although hypothesis-free analysis tools designed for shotgun metagenomics data, such as QIIME (), MetaPhlan (), and Kraken2 (), can be repurposed for the analysis of targeted enrichment data, these are designed simply to quantify and report relative taxonomic abundance and/or richness in the sample, rather than to detect a finite set of organisms of interest.
From an analysis perspective, targeted sequence data have several attractive features that distinguish it from shotgun metagenomic data. First, the panel of targets is pre-defined, making it possible to use established, highly efficient reference-based mapping strategies for sequence processing, with only minor modifications. Second, since a background level of (un-targeted) metagenomic reads remains in the sequenceable library, the difference in read depth between the targeted and untargeted sequences can be used to calculate efficiency of capture, helping to distinguish true low-abundance positives from low-level background reads. Targeted sequencing combined with reference mapping also allows for read de-duplication, and therefore lends itself to quantitative analysis of input material, equivalent to estimating pathogen load directly from sequence data, as has been demonstrated for estimation of pathogen abundance in HIV (), RSV (, ), and other organisms (). Although these features of targeted sequencing are likely appreciated within laboratories that use capture, wider uptake of targeted sequencing requires bioinformatics tools to support the specific features of the laboratory method.
Here, we present the Castanet pipeline (hereafter ‘Castanet’), an end-to-end, automated pipeline specifically designed for the analysis of targeted sequencing data. Our motivation was to create an efficient, easy-to-use, modifiable pipeline that enables rapid processing of a targeted sequencing experiment, and outputs all relevant metrics for downstream analysis. Castanet produces consensus sequences for targets identified in the data, along with summary statistics per target and per organism. It is driven by a robust workflow management system based on an application programming interface (API), which coordinates data versioning, output data management, testing, error management, and concurrency features.
User input to Castanet consists of paired read files (FASTQ with or without compression) and a mapping reference (FASTA file) containing one or more targets of interest. An option exists for users to supply pre-mapped reads (BAM format instead of FASTQ).
Castanet is based on several open source tools, as well as additional methods for classification and quantification (Fig. 1) based on aggregation of reads by organism across multiple target sequences. This depends on an initial mapping to a collection of target sequences (the ‘mapping reference’). The reference will normally reflect the set of targets against which the capture probes were designed, although need not match precisely, as the selective amplification of specific targets enables prior assumption of sequence composition within a sample. Control strategies can be supported; for example, a reference sequence that contains both a targeted and an untargeted region can be used to estimate enrichment efficiency.
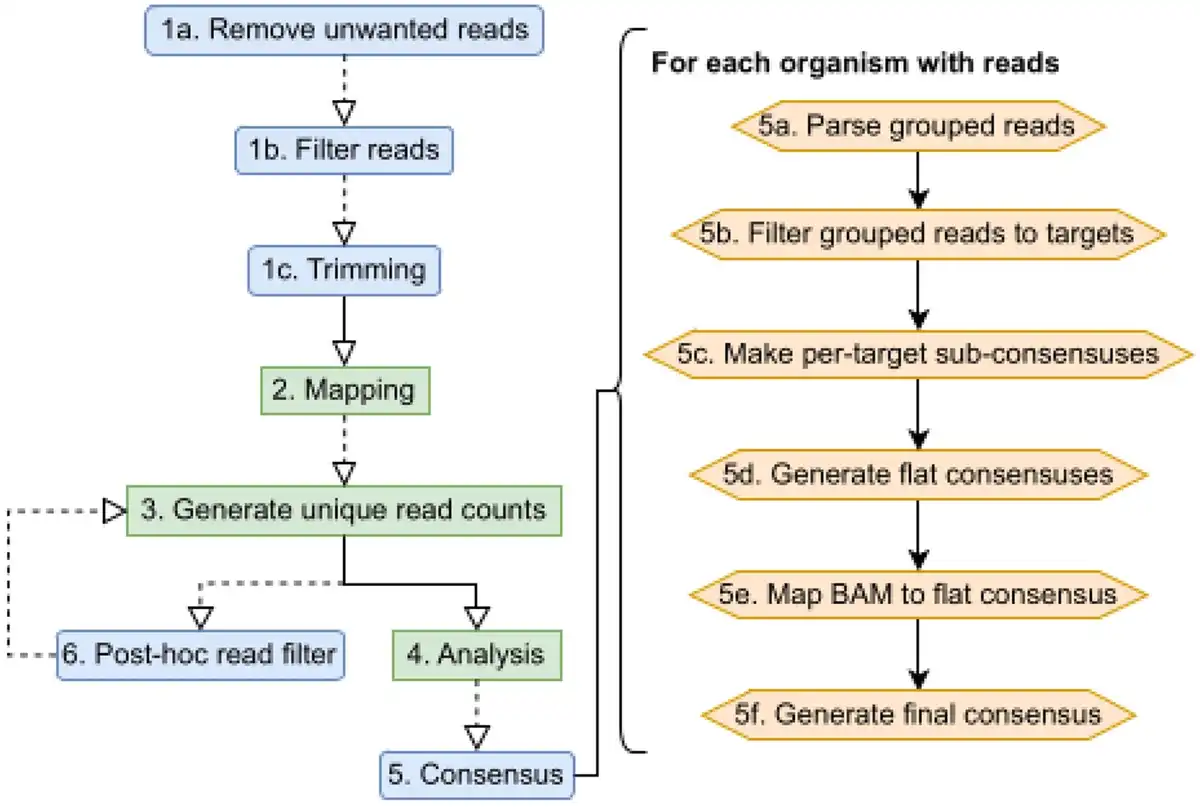
Figure 1
Castanet process flow. (Left) Castanet pipeline. Blue boxes are optional stages. (Right) Consensus generator algorithm.
Castanet’s analytical functions are species-agnostic and examine the comparative distribution of duplicated and deduplicated (unique) reads and their genomic positions. This allows for estimation of pathogen abundance, analysis of capture efficiency and efficient elimination of background reads. Aggregation of reads mapped to multiple targets to the level of individual organisms is achieved by interpretation of target nomenclature via natural language processing functions, according to defined rules. Statistics are then generated for every organism where reads have been detected, including coverage, number of targets/loci mapped, amplification rate, and read proportions.
Consensus sequences are additionally generated where coverage is sufficient, via an algorithm that generates ‘sub-consensuses’ for each target before they are flattened (taking majority bases from a partial alignment of reads and reference sequence) and reads are re-mapped to this as a reference. This alignment is used to generate the final ‘remapped consensus’, using ViralConsensus (). The workflow is amenable to generating bacterial, fungal and parasite consensus sequences, as well as viruses. Crucially, Castanet’s consensus reconstruction does not derive spans of consensus sequences from their references, which allows for more precise downstream analyses such as strain typing.
Castanet was originally written as an in-house research tool (), implemented in Python 2 (https://github.com/tgolubch/castanet); this experimental version has been publicly available since 2019 and has been in extensive use within our own laboratories since 2018. To maximize the utility of the software for the bioinformatics community, we have now updated, optimized, fully automated and substantially expanded functionality to include consensus calling and utility functions. Aims for the Castanet application included:
User friendliness. Extensive bioinformatics experience is not required to install and run the software. Users may run jobs from either a simple command-line interface (CLI) or a browser-based graphical user interface (GUI). An API is available for expert users. Documentation is provided as a Wiki in the GitHub repository.
Continuous Integration/Continuous Development (CI/CD) and Workflow management. Castanet is containerized with Docker and automatic build scripts are included for local installations. The API workflow model enables reproducibility, robustness and scaling features and a combination of pre-commit Git hooks and PyTest suite ensures code quality.
Automation. No manual curation is needed to run Castanet other than ensuring the mapping reference is generated as a standard multi-fasta file with an appropriate sequence naming convention.
Performance. A paired read file of approx. reads may be analysed in under 5 minutes, on a consumer-grade laptop with a 16 thread 3.30 GHz processor and 32 Gb RAM.
Here we detail experiments validating Castanet and conclude by critically evaluating results in the context of the current gold standard methods.
2 Materials and methods
2.1 Software
Castanet is written in Python 3.10 and is native to Ubuntu 22.04, but is also compatible with all Linux-like environments including Mac. The application is hosted on a lightweight Uvicorn server behind which workflows are managed by a RESTful API composed in FastAPI (https://github.com/tiangolo/fastapi). The application also has a simple command-line interface (CLI). Users may opt to use the CLI, or to run jobs from the standalone dashboard via a browser. All external dependencies may be installed via a shell script included in the repository. A full README and documentation WIKI are included in the repository.
Individual pipeline stages (Fig. 1) are detailed below, with external dependencies listed in bold. The pipeline may be run as a single end-to-end process; a batch process that will iteratively fire end-to-end runs for all samples within a single directory; or individual pipeline stages. Users may, for example, skip steps 1–4 if they already have a BAM file of reads mapped against their chosen reference.
(Optional) Pre-process data:
Taxonomically classify reads (call Kraken2).
Filter out unwanted reads based on taxonomy, e.g. arising from the host genome.
Trim adapters and remove low quality reads (call Trimmomatic; ).
Map cleaned reads to reference sequences to produce a BAM file containing all mapped reads, including improper pairs (call BWA-mem2; , SAMtools).
Parse BAM file:
Aggregate reads by target. Remove spurious matches falling below a user-defined threshold on fragment length (TLEN). Improperly paired reads are allowed if the paired mate matches another variant of the same target (e.g. another variant of a targeted virus), and is of sufficient mapped length.
Generate total and unique (position-deduplicated) read counts.
Temporarily cast reads grouped by target to separate BAM files.
Call analysis functions:
Parse reference lengths, merge with position counts.
Aggregate target sequences as organism-locus, via regular expressions. Organism-locus can be understood as a group of non-homologous regions that comprise the entirety of targeted sequence for a specific organism, e.g. multiple genes from a bacterial genome.
Generate statistics for each organism-locus.
Generate approximate coverage plots for each organism-locus.
Reconstruct consensus sequences (Fig. 1). Gaps in genomes with incomplete coverage are not filled by the reference. For each organism with reads:
Parse all reads grouped by target from step 3.
For each organism with reads, filter reads to each individual target, via collation from step 4.
Generate per-target ‘sub-consensus’ sequences (SAMtools).
Create ‘flat consensus’: Filter master BAM to organism-specific targets with coverage and depth exceeding user-specified thresholds and align sub-consensuses with relevant reference sequences, then generate a consensus (SAMtools, Mafft ()).
Remap filtered master BAM from step 2 to flat consensus (BWA-mem2). RGB LED Tape Extension Lead.
Call final consensus on remapped flat consensus (ViralConsensus).
(Optional) Output of analysis (misassigned reads) used to filter input BAM file, re-call step 3 (SAMtools).
2.2 Experimental evaluation
To evaluate Castanet, we used five datasets: Two synthetic and three real (Table 1). To focus the testing strategy on what is a primary use of Castanet in our laboratory, all experiments focused on detection of viral agents. We used a mixture of data with unknown (set A) and known (set B) genomic content to compare Castanet’s utility in both ‘real-world’ and benchmark contexts.
For set A (ENA PRJEB77004), Castanet was used to analyse a dataset generated in-house (Supplementary Document 1, S1) via target capture as a simulated clinical application and included:
A.1 Viral multiplex reference (National Institute for Biological Standards and Control, London, United Kingdom). Pre-mixed material from 25 viruses of human and bovine origin, of which the following were quantified in International Units: Parechovirus (HPeV), human herpes virus 4 (HHV4, more commonly known as Epstein-Barr virus, EBV), human herpes virus 5 (HHV5, more commonly known as cytomegalovirus, CMV). This control was included as a dilution series to support estimation of viral load.
A.2 Five pooled clinical plasma samples from healthy donors, confirmed as PCR-negative for multiple infectious agents including HIV, Hepatitis B, C, and E. These were included as being representative of negative samples in a screening context that nevertheless could contain low numbers of reads for adventitious, non-pathogenic viruses such as torque teno virus (TTV).
Set B included both simulated (set B.1, Supplementary Document 1, S2) and publicly available data (set B.2). These included:
B.1.1 Marburg virus is a filamentous negative-sense ssRNA virus with three distinct clusters where intra-species nucleotide divergence is % (). This represents a straightforward use case where retrieval of the entire genome is feasible through use of a small number of probes.
B.1.2 Hepatitis C virus (HCV), equal mixture of reads from types 1a, 2a, and 2b genotypes. This simulates a complex but relatively common clinical issue where multiple viral subtypes or quasi-species may co-exist within a patient (). As a short positive-sense ssRNA virus, full genome coverage may easily be achieved with a small number of probes.
B.2.1 RSV. 17 clinical respiratory samples extracted from nasal swabs, in infants infected with this linear negative-sense ssRNA virus (ENA ERR10812874–86) (). Samples were collected from UK and Spanish infants aged less than one year during the 2017–18 RSV season for the purpose of investigating virus subtype distribution and differential gene expression in this outbreak. The original study identified and published several diverse, novel isolates through a curated workflow using Shiver (); the current study did not omit the four samples that the original study’s authors were not able to extract reference sequences from.
B.2.2 HIV-1. 21 clinical blood samples from individuals known to be HIV-1 positive, collected as part of a pan-European project (ENA ERR732065–90) for the purpose of providing open source data for HIV researchers (, ). HIV is retroviruses possessing duplicate copies of positive-sense ssRNA genomes whose capability for rapid mutation frustrates efforts to treat and study it (); hence, reconstruction of HIV genomes from NGS data is challenging because an individual with HIV is likely to be host to multiple quasi-species of the virus with significant intra- and inter-host divergence. HIV-1 sequences were pre-determined using a simple pipeline of Iterative Virus Assembler (IVA) () followed by Shiver, using default settings for both.
Descriptive statistics were collected including number of mapped reads, mean depth, coverage at depths 1 and 10, mean amplification rate (MAR, number of reads ÷ number of deduplicated reads at each position supported by reads), and consensus sequence quality were recorded from Castanet’s default output. Consensus quality was measured by comparing Castanet’s output with published reference sequences, using BLASTn (query coverage and percentage identity, hits where E values ) and Mash scores (). The rationale for adopting two metrics was that Mash is a more sensitive tool and hence provides more information in instances where BLAST scores are very high.
We used an in-house mapping reference of 3682 sequences against a range of clinically relevant viral, fungal, parasitic, and bacterial targets, including ribosomal multi-locus (rMLST) () targets for the latter, in all experiments. Castanet’s default settings were used throughout.
2.2.1 Hardware
All experiments were conducted on a laptop with 16 hyperthreading-enabled cores (i9-11980HK, 3.30 GHz), 32 Gb DDR4 RAM and M.2 SSD with read/write speed of Mb s−1, running Windows Subsystems Linux Ubuntu 22.04 LTS. Experiment run time was benchmarked in all experiments.
3 Results
The average run time for a single sample across all experiments conducted between sample sets A–B was 7.28 min (mean read depth ), the longest run in 31.0 min which comprised over reads and involved generating consensus sequences for four organisms. Benchmarking is included in the SI (Supplementary Document 1, S3).
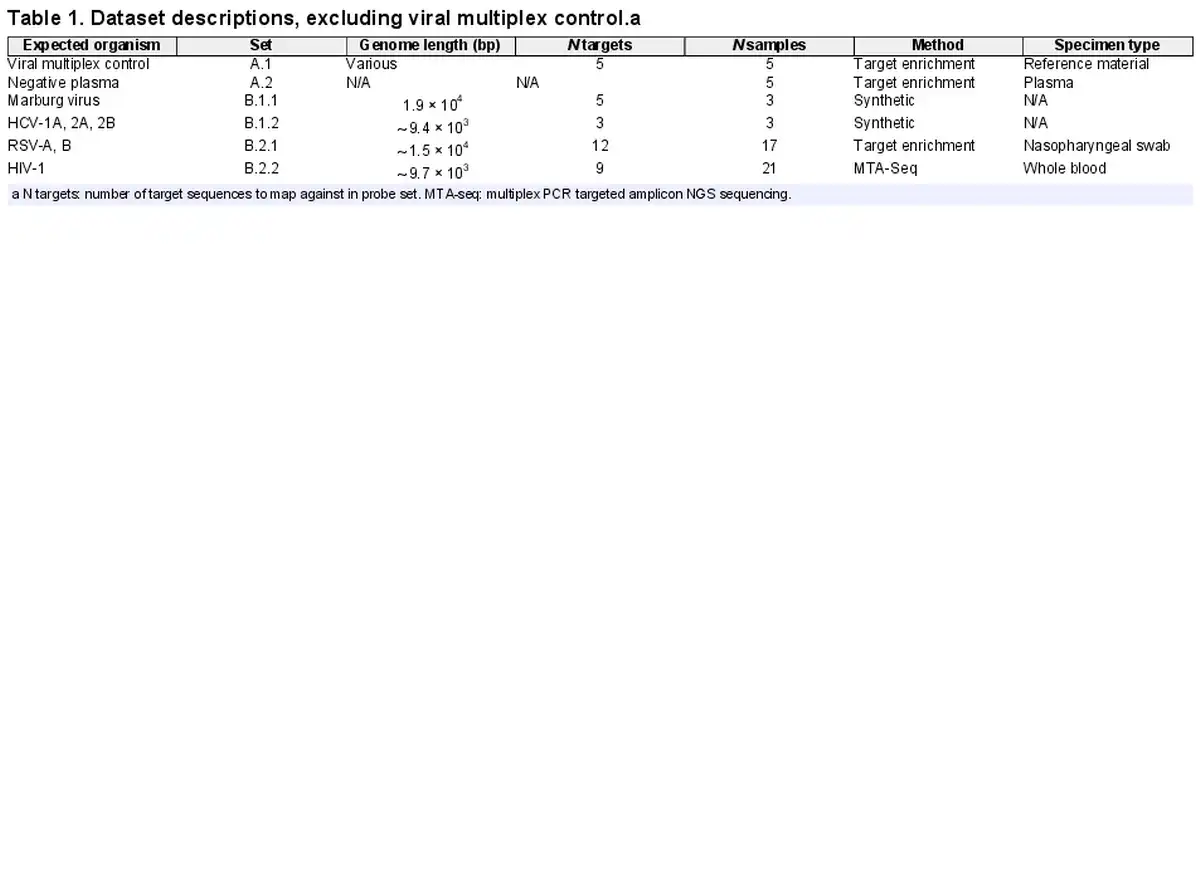
For detected organisms of interest, plots of read depth across the span of each genome for both deduplicated (unique) and total reads were generated automatically by Castanet (Fig. 2a and b). These were used to assess coverage and, in the case of pre-quantified controls, estimate viral loads (Fig. 2c) using linear least squares regression of log10 of deduplicated reads reported by Castanet versus log10 of known laboratory-reported viral load from qPCR experiments, in the three viruses from set A.1 (HPeV, EBV, and CMV).
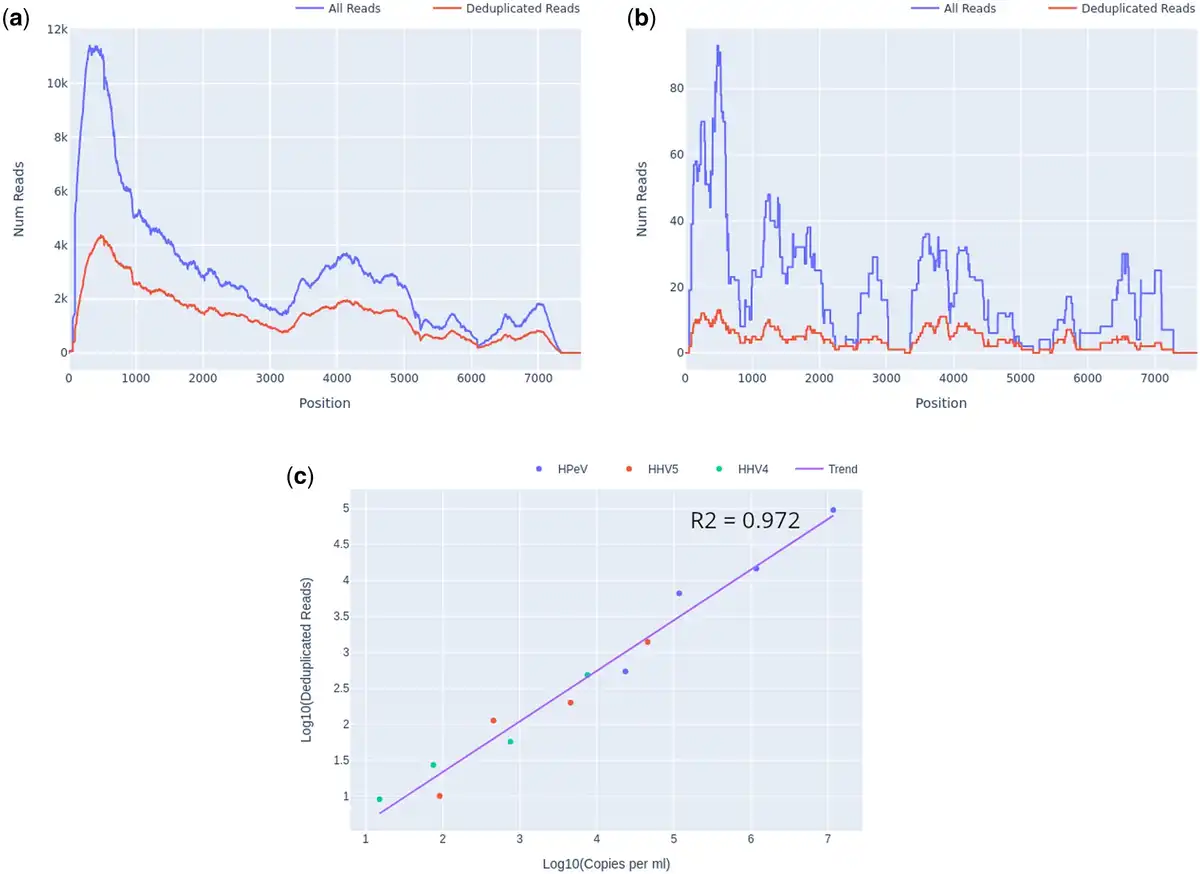
Figure 2
Castanet output for set A.1, at several dilutions. (a) Read depth graph showing total and deduplicated (unique) reads for HPeV, undiluted, viral load 9.6 × 104 copies per ml. (b) Read depth, HPeV, 1:500 dilution, 5.3 × 102 copies per ml. (c) Log10 deduplicated reads versus Log10 copies per ml for HPeV, HHV4, and HHV5 at four different dilutions (1, 1:10, 1:100, and 1:500), with linear regression line.
A significant benefit of targeted sequencing is that signal of enrichment may be useful for distinguishing true low abundance positives from the background sequences that are a ubiquitous feature of all sequencing experiments (). In our experience, genome coverage plots of low-abundance true positives that have been successfully sequenced with target enrichment are expected to show a characteristic “city-block” appearance, with a series of highly amplified fragments across the targeted regions, which result from capture and amplification of a small number of template fragments in the sample. We observed such patterns in both controls at known low titres (Fig. 2b) and clinical samples where low pathogen abundances were anticipated, e.g. commensal viruses such as TTV (Fig. 3a). In contrast, background sequence noise, such as index misassignment or carryover from other samples in the batch, will have very few or no duplicated reads at the targeted region, with no evidence of amplification which is what we observed (Fig. 3b). It is notable that the use of amplification intensity to distinguish low-abundance positives from background noise is method-specific; it is well suited to targeted enrichment protocols and generally does not apply to shotgun metagenomics, allowing for certain edge cases, e.g. index misassignment, contamination from another library. Consequently, when untargeted shotgun data are analysed with Castanet, the plots can be expected to show very little sequence duplication (Supplementary Document 1, S4).
Figure 3
Appearance of presumptive low positives, false positives, and contamination in read depth plots from set A.2. (a) Reads for TTV, with high amplification rate across the region with reads (4.0), across a partial region of the genome. (b) Trypanosoma spp. reads at the ribosomal 18s locus, with no amplification and incomplete coverage. (c) HBV reads with incomplete coverage and significant amplification (MAR 5.82, SD 3.37).
A common source of difficulties with standard taxonomic classification tools for metagenomics data, which quantify taxa on the basis of read identity, is that reads may originate from a high-abundance contaminating source, such as pre-amplified PCR product. In standard metagenomics processing, such contaminated samples will yield extremely high numbers of reads matching a given taxon and will be considered high-confidence positives. However, using reference mapping, contamination of the sample, e.g. pre-amplified (PCR) product is readily detectable as unusually high depth across a defined proportion of the targeted region, with no evidence of sequence across the rest of the targets for the same organism. An example of this type of contamination is shown in Fig. 3c, where an HBV sample was accidentally contaminated by a small amount of amplified product from a diagnostic PCR in the originating laboratory, seen as a discrete region of high depth at the targeted genomic region, and a smaller region of cross-mapping of some reads to an imperfect genomic repeat of the target. Castanet uses mapping to make this analysis intuitive.
Another crucial process in analysing a target enrichment experiment is estimating the efficiency of capture, as many downstream applications rely on amplification of target sequences being sufficient to achieve adequate coverage and read depth to properly represent sample diversity. This may be achieved with Castanet’s output in several ways, including by comparing the mean sequencing depth between targeted and non-targeted sequences. Non-targeted sequences are part of the uncaptured (metagenomic) background, and hence would be expected to have little-to-no evidence of read duplication, whereas targeted sequences should have significant amplification (100– the background) in cases where capture has been successful. In a representative example from set A.2, we found the read depth to be that of the metagenomic background when comparing read depth of the whole human mitochondrial genome (Fig. 4a) with cytochrome C oxidase I (COX-1) (Fig. 4b), where the latter was the only targeted region in the former.
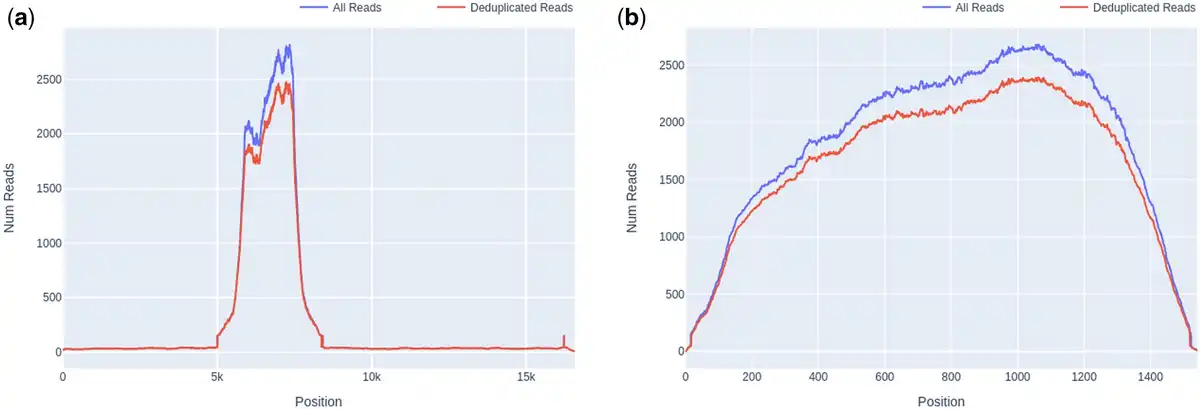
Figure 4
Comparison of read depth between untargeted and targeted sequences, in a screened pooled human plasma sample (set A.2). (a) Whole human mitochondrial gene, median depth 16 (excluding COX-1 region). (b) Targeted sequence, mitochondrial COX-1, median depth 2109.
A primary novelty of Castanet is its aggregation of reads to the correct organism, which it did correctly in all experiments from set B (Table 2). For consensus reconstruction, counts as low as were sufficient to recover the vast majority of genomic content in all experiments. For detection of organisms where a complete genome is not required, a significantly lower read number (approximately ) was sufficient.
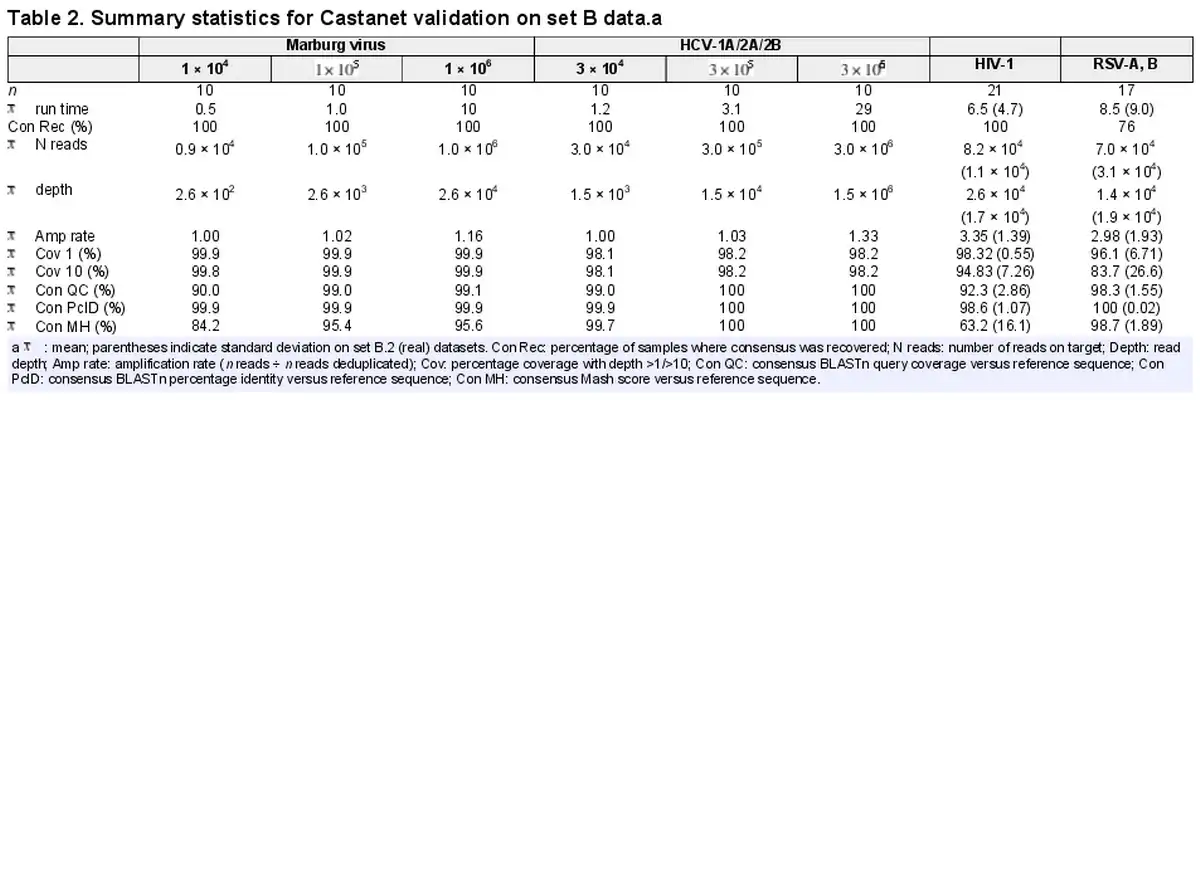
The quality of consensus sequences, measured via BLASTn and Mash scores comparing Castanet consensuses to reference sequences, increased to peak values exceeding 99% (BLASTn QC/PcID) and 95% (Mash) at read counts exceeding in set B.1. We were able to differentiate between and generate consensus sequences that approached 100% identity with reference sequences, for all three HCV subtypes in set B.1.2. Reads on target (i.e. mapped to the reference) in the order of were retrieved in both B.2 datasets, which was sufficient to generate coverage exceeding 83% in all cases, or 94% if excluding the four insufficient RSV samples. These four RSV samples had much lower mean coverage (mean 85.5%, SD 6.20% and mean 45.0%, SD 25.4% at depth 1 and 10, respectively) and MAR than other samples, although consensus sequences with sufficient coverage to support strain typing were generated for all, where this had not been achieved previously.
4 Discussion
Castanet is designed to provide outputs of greatest interest to those running targeted multi-organism sequencing experiments, but is broadly applicable to sequence data generated using other methods. Reporting of statistics such as coverage and depth is essential in any sequencing workflow, as these indicate the relative success of the experiment and whether downstream analyses such as variant discovery will be possible. Castanet reports additional statistics such as MAR (an amplification of 1 indicates poor enrichment, or no enrichment or contamination): we used this in set B.2.1 experiments to demonstrate correlation of failure to recover a consensus genome with low amplification, which could result from experimental factors such as sample insufficiency. The full Castanet analysis output (Supplementary Spreadsheet 1, Sheet 1) encompasses 51 statistics which allow for flexible characterization of experimental data depending on experimental design.
Although we focused our reporting on the most abundant organisms in the samples described here, a range of other organisms were detected in the majority of B.2.1 samples including expected viral and bacterial species (human rhinovirus, Moraxella catarrhalis, Haemophilus influenzae among others) (Supplementary Spreadsheet 1, Sheet 2). This highlights the utility of Castanet for rapid and comprehensive analysis of target capture data to characterize a wide variety of organisms in a single workflow which could be applied to diagnostic microbiology settings.
The quantitative relationship between deduplicated read counts and a sample’s viral load, described extensively in previous publications (, , ), further illustrates how Castanet’s output may feasibly be used in conjunction with target capture methods to complement or, in specific circumstances, replace PCR testing in a diagnostic setting, provided sufficient quality control and calibration provided for as part of the workflow. While it is beyond the scope of this study to estimate the time and monetary cost of such a move, contemporary studies have demonstrated that NGS may offer significantly reduced costs over PCR when deployed at scale when analysis of multiple targets is required, such as cancer biomarker testing (), mass HIV screening (), and Mycobacterium tuberculosis testing in public health settings ().
Contamination is a recognized risk in all high-throughput sequencing workflows, with multiple potential sources for it to be introduced into a library. Deriving the consensus sequence directly from initial analysis can help troubleshoot the likely source of contamination, e.g. in the case we examined (Fig. 3a), the contaminant was traced to PCR amplicon from a neighbouring laboratory source. We have found that a coverage proportion at minimum depth 2 of — to be a good indicator of likely true presence in problematic samples with low read depth, and is usually confirmatory, although these precise thresholds will differ between laboratories, methods, and target organisms, so should not be considered without reference to the amplification rate. This highlights another justification for the use of target capture methodologies in high-throughput settings when leveraged via Castanet.
Users may evaluate coverage per-target and fine-tune consensus generation parameters where necessary, using the automatically generated consensus alignment plots (Supplementary Document 1, S5). This is relevant in cases such as set B.1.2, as it was known a priori that three distinct HCV variants were present. Default Castanet behaviour would aggregate all reads to “Hepatitis C” and generate a consensus sequence represented by the majority subtype. There are multiple options for extracting more precise genotyping data from Castanet, such as modification of mapping reference nomenclature, use of a separate mapping reference file where aggregation is allowed only at the level of subtypes, or extracting multiple sub-consensuses from the consensus module’s output. It may be sufficient for most workflows, however, to confirm the presence of reads against a specific organism with Castanet and use the consensus sequence to compare bulk genomic data between samples before doing downstream strain typing.
All consensus quality scores were lower in set B.2.2 experiments (against set B.2.1, consensus query coverage 92.3% versus 98.3%, percent identity 98.6% versus 100%, Mash score 63.2% versus 98.7%), as would be expected for viruses such as HIV-1 that form diverse intra-host populations, as alignment involves taking majority values across all sub-consensuses. In such cases, it is possible to extend Castanet to add a species-specific workflow once the correct pathogen has been identified. HIV-1 data used for benchmarking in this study were generated with MTA-seq, which highlights the utility of the Castanet pipeline for different NGS techniques.
Comparisons of Castanet with the software used to generate reference sequences are included here to guide users towards the appropriate choice of analytical pipeline. In the case of our most difficult example, HIV, shiver was specifically designed for optimal reconstruction of HIV genomes from highly diverse clinical samples, by regenerating missing regions from the closest-matching reference sequence from a user-defined library, or from de novo-assembled contigs. This requires a curated database of reference sequences and possibly expert input to evaluate the quality of alignments before contigs are flattened with the references. Castanet output is suitable for further processing with shiver or other software, but we chose not to implement additional specific workflows within the tool itself.
We have presented Castanet’s method of aggregating reads to specific targets at the level of organisms as a feature, but it is pertinent to note two limitations. First, the naming conventions of the user’s probe file must be kept consistent to ensure organism-level aggregation; three regular expressions are provided in Castanet’s documentation to guide users, and our future work includes further refinement of this step. Second, for consensus reconstruction, we assume genome collinearity with references, sample colonization by a meaningful majority quasi-species per organism, and a theoretical coverage of 100% across the targeted regions per organism. In cases where only part of an organism’s genome is targeted, we recommend that the user defines the reference sequences appropriately to match the targeted regions, or sets the consensus parameters in line with a reduced requirement for genome coverage. This is true particularly where larger genomes such as those of bacteria or fungi are only partially represented in a user’s target enrichment panel, and thus Castanet would not be expected to recover a complete consensus genome but only the sequences of targeted regions. In general, the reference should be provided in accordance with the design of the experiment. Multipartite genomes (e.g. segmented viruses or multiple arbitrary genes from a single species) may be processed as separate segments or concatenated into a linear approximation. We have automated multi-gene concatenation specifically for bacterial ribosomal MLST (rMLST) genes (). Future work includes expanded support for multi-locus targets and segmented viral genomes.
Targeted sequencing is well-suited to diverse applications in both research and clinical practice, including pathogen genomics and transcriptomics. The capacity of large diagnostic laboratories to perform sequencing has increased greatly over recent years. As costs continue to fall, targeted sequencing is likely to supersede methods such as 16S sequencing to become part of the routine diagnostic armoury in clinical settings as combined diagnostic and surveillance testing. The Castanet pipeline facilitates bioinformatic analysis to take place outside research facilities, as it addresses the lack of open-source, end-to-end tools designed specifically to exploit targeted sequencing data and hence supports wider adoption of these technologies. Our analysis here has demonstrated how the software may be used to support a wide variety of applications as well as evaluate run performance and troubleshoot laboratory issues, in a scalable and reproducible manner.
Acknowledgements
The authors are grateful to Prof. Martin Maiden for his guidance in implementing rMLST gene compatibility of our capture oligos and mapping reference.
References
- Alborelli I, Generali D, Jermann P et al Cell-free DNA analysis in healthy individuals by next-generation sequencing: a proof of concept and technical validation study. Cell Death Dis2019;10:534.
- Ansari MA, Aranday-Cortes E, Ip CL et al; STOP-HCV Consortium. Interferon lambda 4 impacts the genetic diversity of hepatitis C virus. Elife2019;8:e42463.
- Bestvina CM, Waters D, Morrison L et al Cost of genetic testing, delayed care, and suboptimal treatment associated with polymerase chain reaction versus next-generation sequencing biomarker testing for genomic alterations in metastatic non-small cell lung cancer. J Med Econ2024;27:292–303. .
- Blanco-Míguez A, Beghini F, Cumbo F et al Extending and improving metagenomic taxonomic profiling with uncharacterized species using MetaPhlAn 4. Nat Biotechnol2023;41:1633–44. .
- Bolger AM, Lohse M, Usadel B. Trimmomatic: a flexible trimmer for illumina sequence data. Bioinformatics2014;30:2114–20. .
- Bolyen E, Rideout JR, Dillon MR et al Reproducible, interactive, scalable and extensible microbiome data science using QIIME 2. Nat Biotechnol2019;37:852–7.
- Bonsall D, Ansari MA, Ip C et al; STOP-HCV Consortium. ve-SEQ: robust, unbiased enrichment for streamlined detection and whole-genome sequencing of HCV and other highly diverse pathogens. F1000Res2015;4:1062.
- Bonsall D, Golubchik T, de Cesare M et al; Sep HPTN 071 (PopART) Team. A comprehensive genomics solution for HIV surveillance and clinical monitoring in Low-Income settings. J Clin Microbiol2020;58:e00382–20.
- Goh C, Golubchik T, Ansari MA et al Targeted metagenomic sequencing enhances the identification of pathogens associated with acute infection. bioRxiv,2019, preprint: not peer reviewed.
- Hargrave A, Mustafa AS, Hanif A et al Current status of HIV-1 vaccines. Vaccines (Basel)2021;9:1026.
- Hunt M, Gall A, Ong SH et al IVA: accurate de novo assembly of RNA virus genomes. Bioinformatics2015;31:2374–6.
- Jenkins F, Le T, Farhat R et al Validation of an HIV whole genome sequencing method for HIV drug resistance testing in an Australian clinical microbiology laboratory. J Med Virol2023;95:e29273.
- Jolley KA, Bliss CM, Bennett JS et al Ribosomal multilocus sequence typing: universal characterization of bacteria from domain to strain. Microbiology (Reading)2012;158:1005–15.
- Jurasz H, Owski T, Perlejewski K. Contamination issue in viral metagenomics: problems, solutions, and clinical perspectives. Front Microbiol2021;12:745076. .
- Katoh K, Standley D. Mafft multiple sequence alignment software version 7: Improvements in performance and usability. Mol Biol Evol2013;30:772–80. .
- Lin GL, Drysdale SB, Snape MD et al; RESCEU Investigators. Distinct patterns of within-host virus populations between two subgroups of human respiratory syncytial virus. Nat Commun2021;12:5125. .
- Lin GL, Drysdale SB, Snape MD et al; RESCEU Consortium. Targeted metagenomics reveals association between severity and pathogen co-detection in infants with respiratory syncytial virus. Nat Commun2024;15:2379. .
- Lythgoe KA, Hall M, Ferretti L et al; COVID-19 Genomics UK (COG-UK) Consortium. SARS-CoV-2 within-host diversity and transmission. Science2021;372:eabg0821.
- Mann BC, Jacobson KR, Ghebrekristos Y et al Assessment and validation of enrichment and target capture approaches to improve mycobacterium tuberculosis wgs from direct patient samples. J Clin Microbiol2023;61:e00382-23. .
- Moshiri N. ViralConsensus: a fast and memory-efficient tool for calling viral consensus genome sequences directly from read alignment data. Bioinformatics2023;39:btad317. .
- Ondov B, Treangen T, Melsted P et al Mash: fast genome and metagenome distance estimation using minhash. Genome Biol2016;17:132. .
- Scarpa F, Bazzani L, Giovanetti M et al Update on the phylodynamic and genetic variability of marburg virus. Viruses2023;15:1721.
- Smith JA, Aberle JH, Fleming VM et al Dynamic coinfection with multiple viral subtypes in acute hepatitis C. J Infect Dis2010;202:1770–9.
- Vasimuddin M, Misra S, Li H et al Efficient architecture-aware acceleration of bwa-mem for multicore systems. In: 2019 IEEE International Parallel and Distributed Processing Symposium (IPDPS). 2019, 314–324. .
- Wood D, Lu J, Langmead B. Improved metagenomic analysis with kraken 2. Genome Biol2019;20:257. .
- Wymant C, Blanquart F, Golubchik T et al; BEEHIVE Collaboration. Easy and accurate reconstruction of whole HIV genomes from short-read sequence data with shiver. Virus Evolution2018;4:vey007.