1 Introduction
The volume of biomedical literature is expanding at a rapid pace, with public repositories like PubMed housing over 30 million publication abstracts. A major challenge lies in the high-quality extraction of relevant information from this ever-growing body of literature, a task that no human can feasibly accomplish, thus requiring support from computer-assisted methods.
A crucial step in such pipelines is the extraction of biomedical entities (such as genes/proteins and diseases) as it is a prerequisite for further processing steps, like relation extraction (), knowledge base (KB) completion () or pathway curation (). As shown in Fig. 1, this typically involves two steps: (i) named entity recognition (NER) and (ii) named entity normalization (NEN) (a.k.a entity linking or entity disambiguation. We refer to their combination as extraction). NER identifies and classifies entities discussed in a given document. However, different documents may use different names (synonyms) to refer to the same biomedical concept. For instance, “tumor protein p53” or “tumor suppressor p53” are both valid names for the gene “TP53” (NCBI Gene: 7157). The same mention can refer as well to different entities (homonyms), e.g. “RSV” can be “Rous-Sarcoma-Virus” or “Respiratory syncytial virus” depending on context. Entity normalization addresses the issues of synonyms and homonyms by mapping mentions found by NER to a KB identifier. This process ensures that all entity mentions are recognized as referring to the concept, regardless of how they are expressed in the text, allowing to aggregate and compare information across different documents.
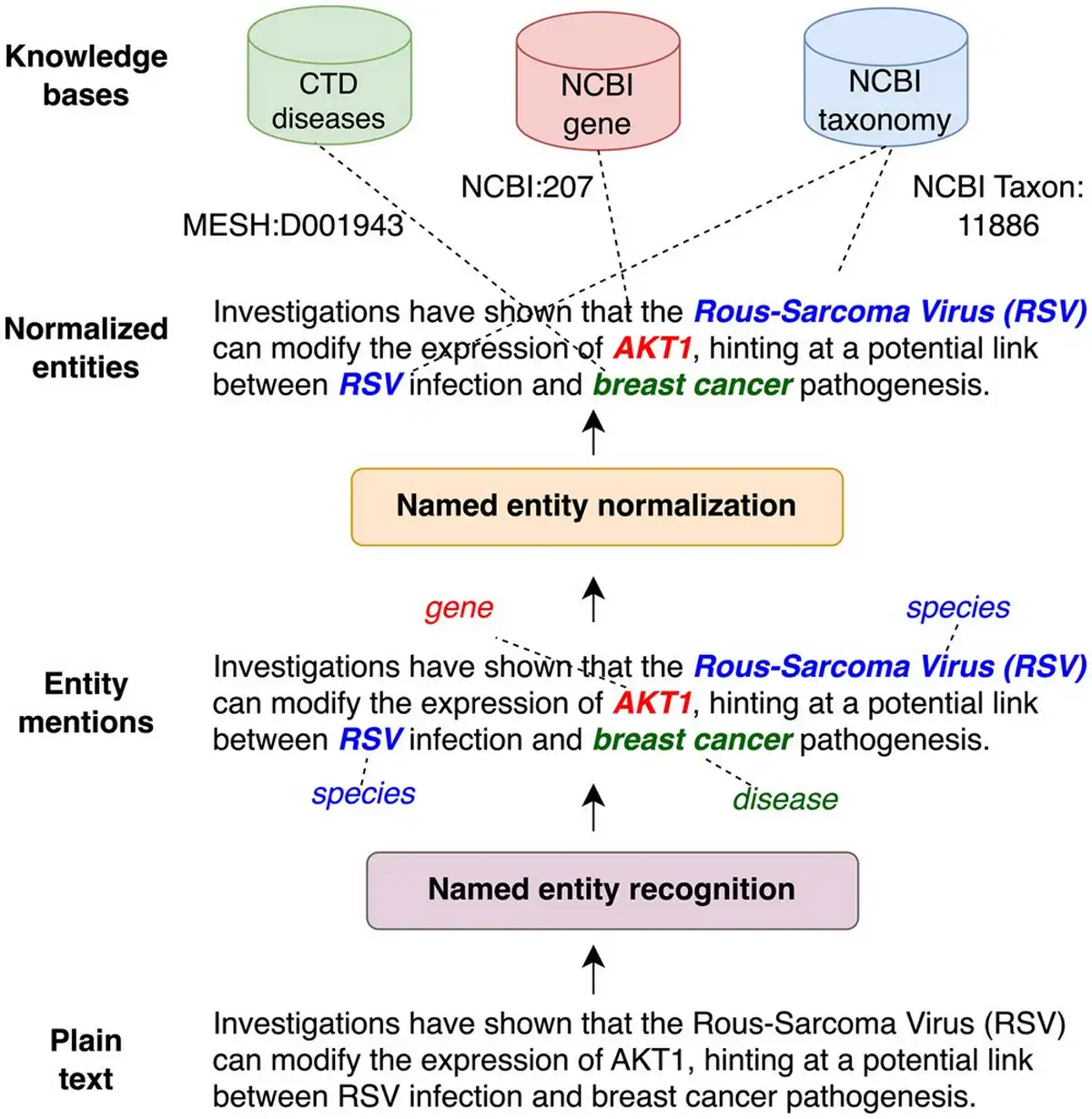
Figure 1
Illustration of named entity extraction. First entity mentions are identified (NER) and then mapped to standard identifiers in a knowledge base (NEN).
Over the last two decades, several studies investigated biomedical NER and NEN. Of the many research prototypes, some have been consolidated into mature and easy-to-install or use tools that end users can apply directly for their specific needs (, , , inter-alia). These tools are commonly deployed “in the wild,” i.e. to custom text collections with specific focus (e.g. cancer or genetic disorders), entity distribution (gene-focused molecular biology or disease-focused clinical trials), genre (publication, patent, report) and text type (abstract, full text, user-generated content). The tools, however, were originally trained and evaluated on a single or few gold standard corpora, each having its own specific characteristics (focus, entity distribution, etc.). The mismatch between these two settings, i.e. training/evaluation versus downstream deployment, raises the question whether the performance in the first can be trusted to estimate the one achievable in the second. As named entity extraction is the cornerstone of several applications, e.g. for relation and event extraction (), the issue has a direct and critical impact on downstream information extraction pipelines.
To better quantify the impact of this issue, previous work proposed to use a cross-corpus evaluation, i.e. training models on one corpus and evaluating on a different one (). For instance, show that the performance of neural networks for NER drops by an average of 31.16% F1 when tested on a corpus different from the one used for training. Previous studies, however, present a few limitations: First, existing benchmarking studies, both in- and cross-corpus, focus primarily either on recognition (, ) or normalization (, ) but do not provide results for named entity extraction, i.e. end-to-end NER and NEN. Secondly, many of them do not account for the latest technologies and models () like pretrained language models.
In this study, we address these limitations and present the first cross-corpus evaluation of state-of-the-art tools for named entity extraction (end-to-end NER and NEN) in biomedical text mining (BTM) to provide an in-depth analysis of their results, highlighting current limits and areas for improvement. After an extensive literature review that identified 28 publications, we select from these five mature tools based on predefined criteria: (C1) supporting both NER and NEN, (C2) integrating recent improvements (e.g. transformers), (C3) extracting the most common entities (genes, disease, chemicals, and species), and (C4) requiring no further licenses (e.g. Unified Medical Language System (UMLS) license). The tools are: BERN2 (), PubTator Central (PTC; ), SciSpacy (), and bent (). In the comparison, we include as well HunFlair2, our novel and extended version of HunFlair ().
We performed extensive experiments on three corpora covering four entity types and diverse text forms (abstracts, full text, and figure captions). The corpora were explicitly selected such that none of the tools (according to their documentation) used them for training. Our results show stark performance variations among tools w.r.t. entity types and corpus, with differences of up to 54 percentage points (pp) when comparing scores to those of previously published in-corpus results. The overall most robust tool was HunFlair2, reaching an average F1-score of 59.97% and the best results in two (chemicals and diseases) of four entity types. PTC scores very close second best on average and best in the other two types (genes and species). Our study highlights the need of further research toward more robust BTM tools to account for change in biomedical subdomains and text types in downstream applications.
2 Materials and methods
We now describe the selected tools and the evaluation framework used to assess their “in the wild” performance, using a cross-corpus evaluation protocol. Intuitively, by applying them to diverse texts not part of their training, we assess their robustness w.r.t. shifts in central characteristics like text types, genres, or annotation guidelines. We stress that our evaluation strictly focuses on tools capable of both NER and NEN. For recent benchmarks on NER and NEN, we refer the reader to and , respectively.
2.1 Tools
We first survey existing BTM tools via Google Scholar. We define a tool to be a piece of software, i.e. (a) either accessible online via an application programming interface (API) or installable locally, and (b) usable off-the-shelf requiring minimal configurations by nonexperts. This results in an initial list of 28 candidates. From these, we selected tools for in-depth analysis based on the following criteria. The tool must:
C1: support both NER and NEN.
C2: use machine-learning-based models (at least for NER).
C3: extract at least genes, diseases, chemicals, and species.
C4: not require additional licenses (e.g. commercial or UMLS license).
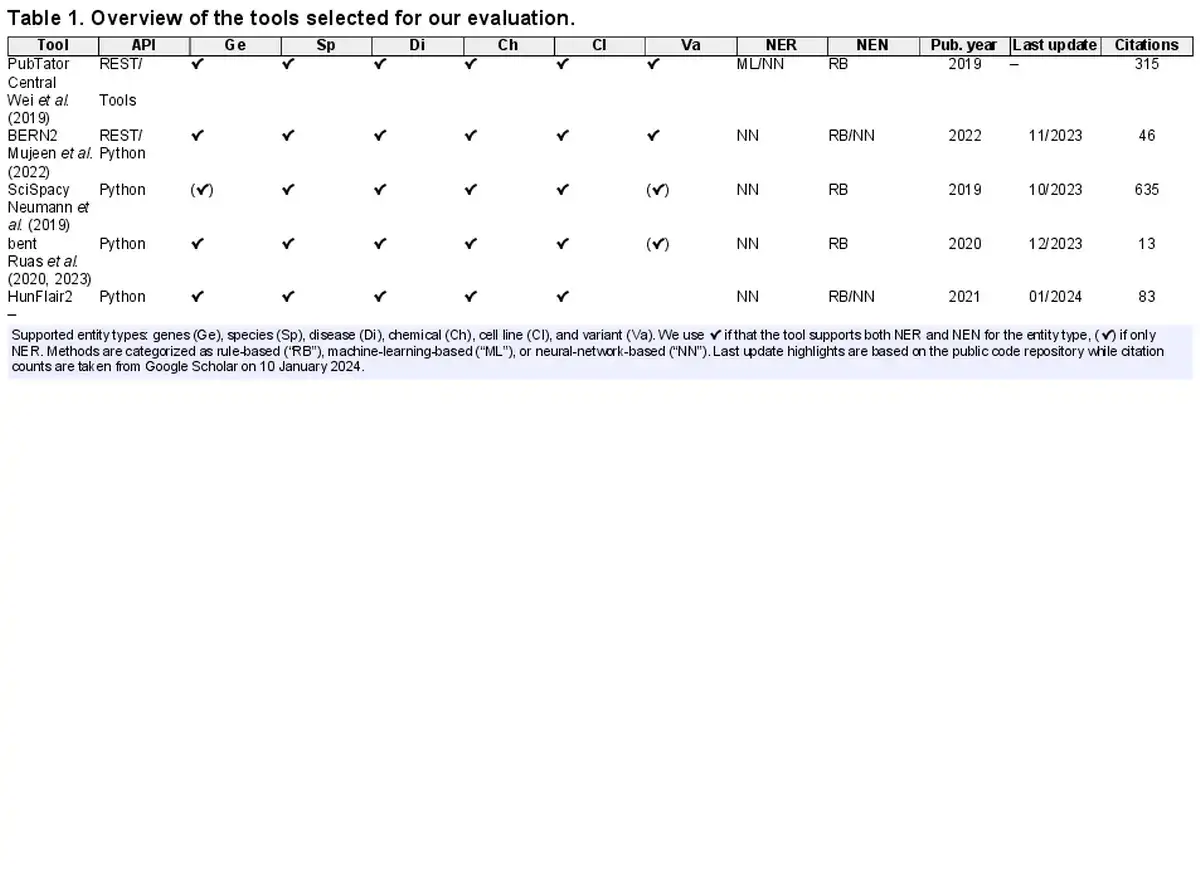
This results in the selection of the following tools (see Table 1 for an overview): BERN2 (), bent (, ), PTC (), and SciSpacy (). An overview of all surveyed tools and details on the selected ones (training corpora, architecture, etc.) can be found in Supplementary Data A. We also provide there an in-depth analysis for HunFlair2, our updated version of HunFlair () which we first introduce here.
HunFlair2 adds to HunFlair (a) support for normalization and (b) an update to the recognition component by replacing the recurrent neural network-based character language models with the LinkBERT pretrained language model (). HunFlair2 supports the extraction of five biomedical entity types: cell lines, chemicals, diseases, genes, and species. For NER, HunFlair2 employs a single model that identifies at once mentions of any entity type instead of training a separate model for each one, inspired by the all-in-one NER approach (AIONER) of . Differently from , we use a natural language template in imperative mode to specify which entity types to extract, e.g. “[Tag genes] <input-example>” to extract genes only and “[Tag chemicals, diseases and genes] <input-example>” for multiple entity types at once. Output labels are assigned using the standard IOB labels, with B-<entity type> and I-<entity type> denoting a particular type. We omit the use of O-<entity type> labels as proposed by and use standard multi-task learning with O labels. HunFlair2’s NER model is trained on: NLM Gene (), GNormPlus (), Linneaus (), S800 (), NLM Chem (), SCAI Chemical (), NCBI Disease (), SCAI disease () and BioRED (). Overall, HunFlair2 improves 2.02 pp over HunFlair across entity types and corpora (see Supplementary Data D). Similar to BERN2, the normalization component uses pretrained BioSyn models () for gene, disease and chemical normalization which link to NCBI Gene (), Comparative Toxicogenomics Database (CTD) Diseases (a.k.a. MEDIC, a subset of MeSH and OMIM) and CTD Chemicals (a subset of MESH; ), respectively. We note that, as in BERN2, the gene model was trained on the BC2GN corpus (), and links exclusively to the human subset of the NCBI Gene (). For species, since there is no available BioSyn model, we rely instead on SapBERT (), a BioBERT model pretrained on UMLS, which includes NCBI Taxonomy (), the species ontology to which we link.
2.2 Corpora
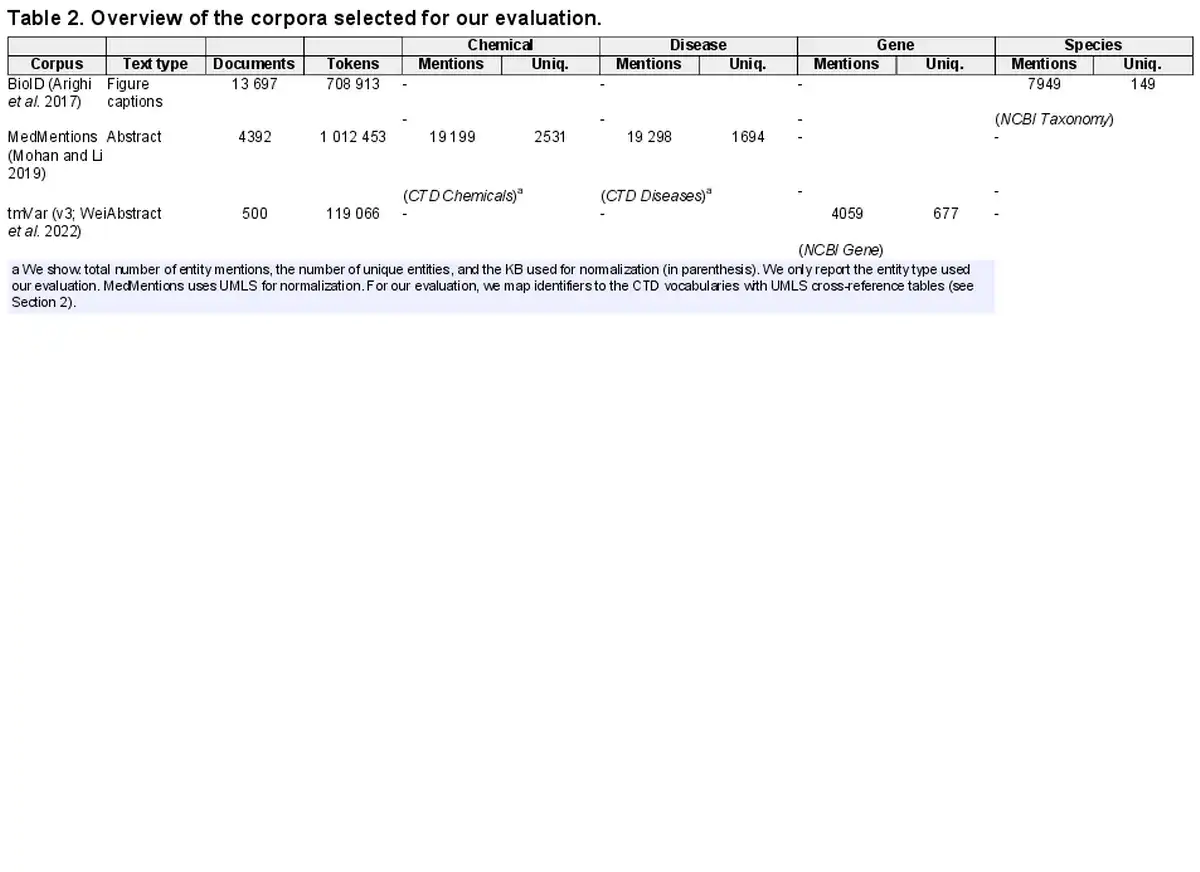
Designing a cross-corpus benchmark for entity extraction poses unique challenges in terms of data selection, as corpora must meet the following conditions: (a) they have not been used to train (train or development split) any of the tools, (b) they contain both NER and NEN annotations and (c) their entity types are normalized to KBs supported by all tools. To ensure these conditions, we select the following corpora: BioID (), MedMentions () (We use the subset ST21pv targeting information retrieval.), and tmVar (v3; ). The corpora present annotations covering four entity types: genes, species, disease, and chemicals, which are linked to NCBI Gene, NCBI Taxonomy, CTD Diseases, and CTD Chemicals, respectively. We note that in MedMentions annotated spans are linked to UMLS (). However, as UMLS provides cross-reference tables with MeSH and OMIM, we are able to map its annotations to the CTD dictionaries and the entity type as either disease or chemical based on the CTD vocabulary to which the identifier has been successfully mapped (We use UMLS 2017AA, the one used to create MedMentions.). We analyze the coverage of this mapping strategy and its impacts on result interpretation in Section 4.4. In Table 2, we present an overview of the corpora (see Supplementary Data B for a detailed description), which we access via BigBio (), a community library of biomedical NLP corpora. As none of the corpora is used by any of the tools, we always use the entire corpus for evaluation rather than their predefined test splits.
2.3 Metrics
For all tools, we report mention-level micro (average over mentions) F1-score. As entity extraction accounts for both recognition and normalization, predictions and gold labels are triplets: start and end offset of the mention boundary and KB identifier. Following , the predicted mention boundaries are considered correct if they differ by only one character either at the beginning or the end. This is to account for different handling of special characters by different tools, which may result in minor span differences (see Supplementary Data E1). A predicted triplet is a true positive if both the mention boundaries and the KB identifier are correct. As in , for mentions with multiple normalizations, e.g. composite mentions (“breast and squamous cell neoplasms”), we consider the predicted KB identifier correct if it is equal to any of the gold ones (We note, however, that these cases are rare: 90 out of 4059 in tmVar v3, 3 out of 7949 in BioID and none in MedMentions.). To address the incompleteness of the UMLS-MESH cross-reference tables while creating the gold standard for chemicals and diseases, we deviate from this general framework in these two scenarios and ignore predictions that exactly match nonmappable entities; i.e. we count them neither as false nor true positives. We treat each annotated entity having a semantic category linked to Chemicals & Drugs and Disorders as potential chemicals and diseases, respectively (see https://lhncbc.nlm.nih.gov/ii/tools/MetaMap/Docs/SemGroups_2018.txt).
3 Results
In Table 3, we report the results (micro F1) of our cross-corpus entity extraction evaluation (see Table 7 in Supplementary Data for precision and recall). First, we note that our results confirm previous findings (, ): when applied to texts different from those used during training, the performance to be expected from current tools is significantly reduced compared to published results (see Section 4.1 for an in-depth discussion). Unlike previous studies, which considered only entity recognition, the drop in performance is even larger, which can be explained by the increased complexity of the task (NER and NEN). The overall best-performing model is HunFlair2, with PTC being second, both having considerably higher average performance than the other three competitors.
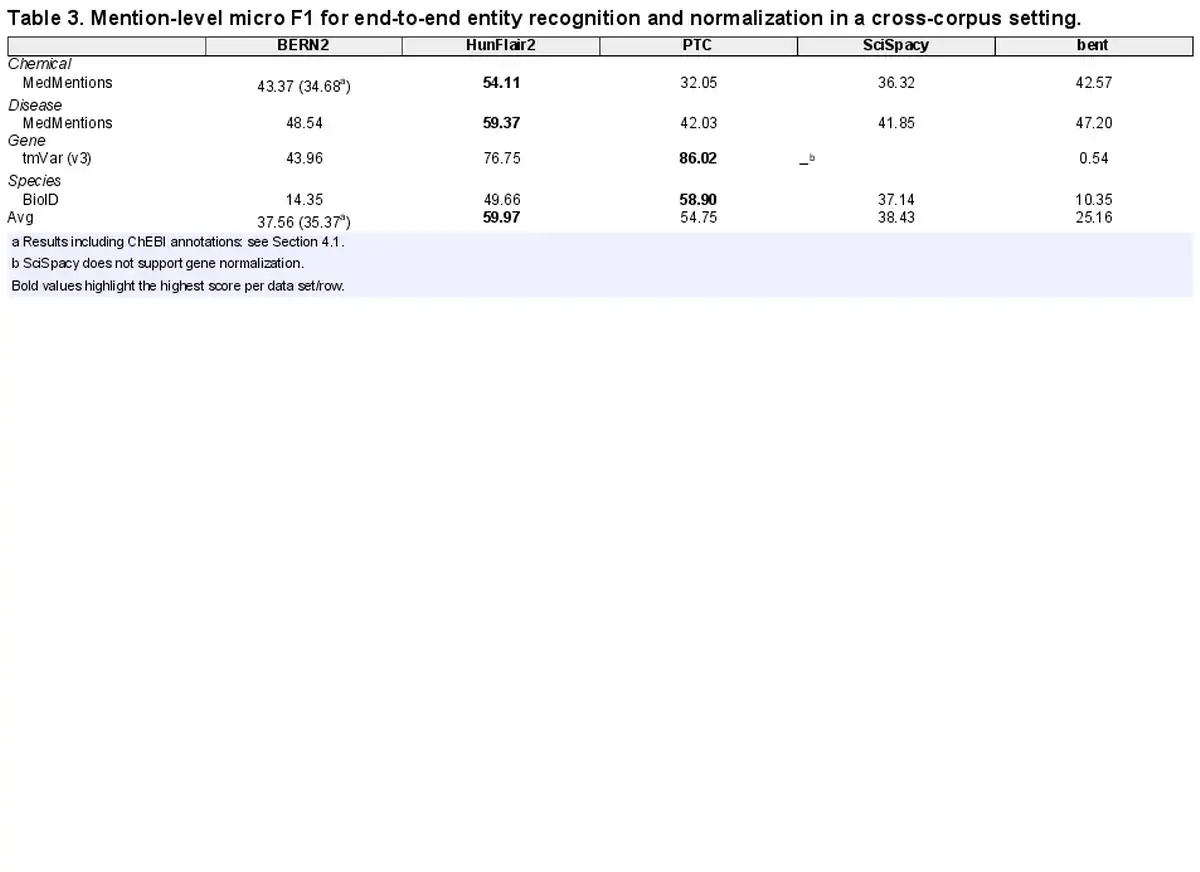
The instances where these two models stand out are the gene and species corpora. For genes, PTC outperforms all models, while HunFlair2 is second. PubTator’s advantage can be explained by its highly specialized GNormPlus system usage. Secondly, as HunFlair2 does not use context information for linking, it cannot effectively handle intra-species gene ambiguity, e.g. “TPO” can be either the human gene 7173 (“thyroid peroxidase”) or 7066 (“thrombopoietin”) depending on the context. Though BERN2 also uses GNormPlus, its performance is notably lower than PubTator’s. This is attributable to its NER component, which introduces many false positives. SciSpacy achieves a subpar performance for chemicals and diseases while scoring third best for species. Finally, we note bent’s exceptionally low score on genes. By inspecting its predictions, we find that this is due to the tool consistently predicting genes of species that are not human. For instance, all mentions of “BRCA1,” instead of being linked to the human gene (672), are linked to the Capuchin monkey (108289781). As 96% of mentions in tmVar (v3) are human genes, this drastically impacts bent’s results. Regarding species, the leading cause for the low performance of BERN and bent are subtle differences in the KB identifiers, primarily for mentions of the mouse concept. Mouse is one of the organisms most frequently mentioned in biomedical publications. In BioID, its mentions are linked to NCBI Taxonomy 10090 “house mouse.” While both PTC and HunFlair2 also return 10090, bent links mentions of mouse to NCBI Taxonomy 10088 (“mouse genus”), while BERN2 to 10095 (“unspecified mouse”), causing a drastic drop in performance. For diseases, we see that differences are not as pronounced with almost all tools achieving >40% F1-score, where we attribute HunFlair2’s advantage to its superior NER performance (see below). Interestingly, BERN2 comes as a close second. We hypothesize this is due to the better performance of its neural normalization components for diseases and chemicals.
4 Discussion
4.1 Cross-corpus versus in-corpus evaluation
The effectiveness of named entity extraction tools is most often measured in an in-corpus setting, i.e. training and test data come from the same source. However, in downstream applications, such consistency cannot be assumed, as tools need to process documents widely different from those used in their training. Therefore, reported performance does not represent how tools generalize to the downstream setting, most likely overestimating their ability to handle variations. A cross-corpus evaluation () allows to (partly) overcome this limitation by training and evaluating on different corpora, thus accounting for variations in text collections (focus, concept definitions, etc.). For instance, as shown in Table 4, we see that both tools report drastically higher scores for an in-corpus NEN evaluation compared to the corresponding cross-corpus one (The only exception is gene extraction with PTC where cross-corpus performance is higher than the in-corpus one. The difference can be attributed to the fact that in tmVar v3 ∼96% of the genes are human, while these are only 48% in NLM-Gene, thus being significantly more challenging due to multi-species gene ambiguity, .).

Establishing a robust and fair cross-corpus evaluation for entity extraction presents, however, its own challenges. A major issue is the difference across corpora w.r.t. mention boundaries, stemming from differences in the annotation guidelines. This can lead to a conflict between training and test annotations, e.g. if one guideline allows composite mentions and the other not (“breast and ovarian cancer” versus “breast” and “ovarian cancer”). As many applications do not require mention boundaries, e.g. semantic indexing (), it is common to measure the document-level performance. Under this setting, we find that results for all tools improve up to 8 pp (see Supplementary Data F3 for details). Related to this issue is the difference in KBs used for normalization. Different corpora and tools often use different KBs; hence, a mapping of identifiers is necessary for a fair comparison, e.g. UMLS in our case (see Section 2). However, cross-reference tables to map concepts between ontologies are not always available. For instance, BERN2 normalizes chemicals both to CTD Chemicals (65%) and ChEBI (35%). However, to the best of our knowledge, no mapping is available between the two. We were therefore forced to modify the BERN2 installation to only use CTD, ignoring many of its normalization results. Finally, minimal variations in the normalization choices can introduce substantial differences in results, as exemplified by the “mouse” case reported in Section 3. This can be mitigated by using evaluation metrics that take into account the KB hierarchy, e.g. the one introduced by , which considers the lowest common ancestor for the evaluation, penalizing predictions according to the KB hierarchy. This is, however, limited to KBs that are structured hierarchically, which is not always the case (e.g. NCBI Gene). The scarcity of corpora with linking annotations further complicates a cross-corpus evaluations. For instance, for cell lines, there are no other corpora than BioID () and JNLPBA (), both of which are used during training by at least one of the evaluated tools. Secondly, we are restricted to corpora which link to ontologies supported by the evaluated tools. Finally, we note that can assess the tools’ performance only on one corpus per entity type, limiting our expressiveness of our evaluation. These limitations must be taken into account when interpreting the results.
4.2 Entity distribution
Corpora are often designed for specific subdomains or applications, e.g. the plant-disease-relation corpus (PDR) () focuses on plants, while BioNLP2013-CG () does on cancer genetics. Consequently, they often present imbalanced entity distributions, with few highly frequent entities and a long tail of rarely occurring ones. For instance, as shown in Table 5, in BioID, the most frequent species is NCBI Taxonomy 10090, accounting for more than half of all mentions in the corpus. This raises the question of how much the performance can be attributed to correctly extracting the most frequent entities. For this, we compute macro-average F1-scores (see Supplementary Data C for details) as well. The results show strong performance degradation in all tools across all entities, most notably for species, which is consistent with the entity distribution in Table 5. We refer the reader to Table 8 in Supplementary Data F2 for complete results (and Table 6 in Supplementary Data E3 for the NER-only equivalent).
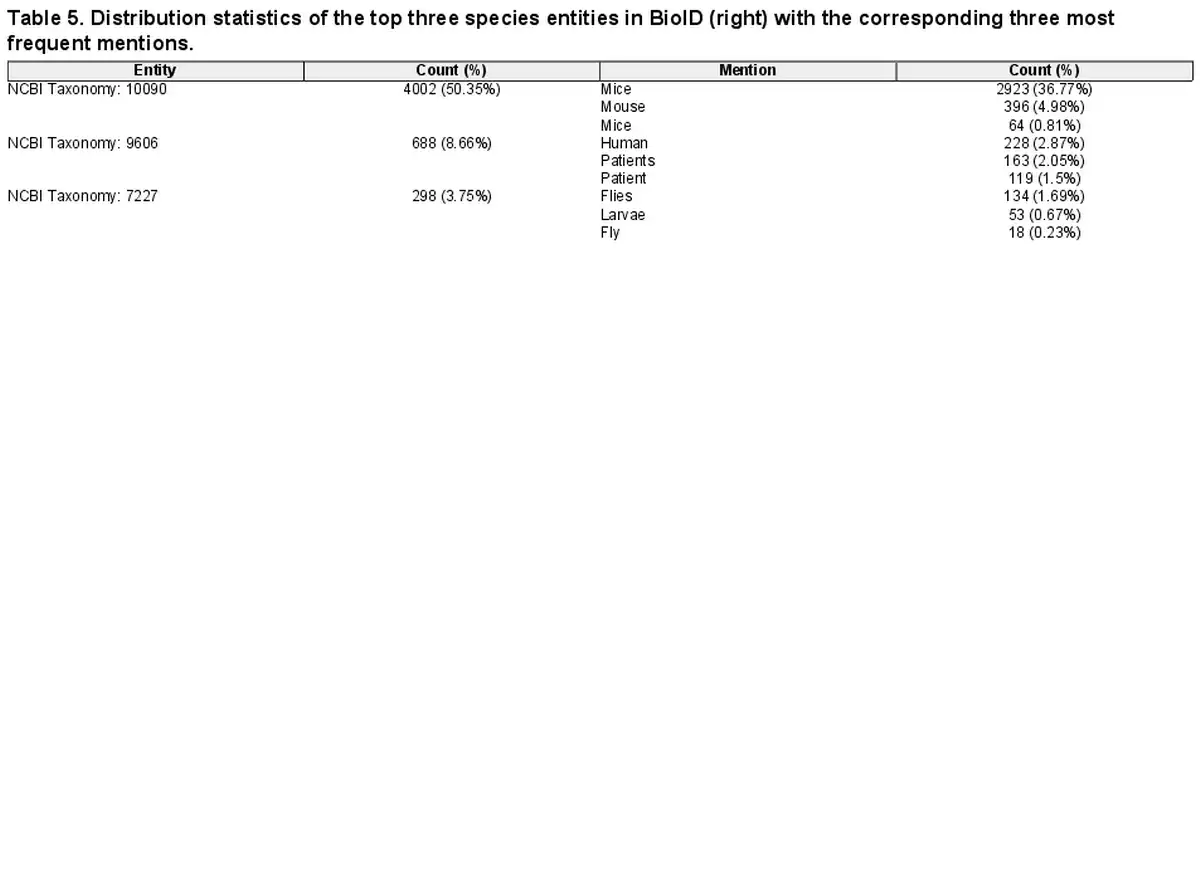
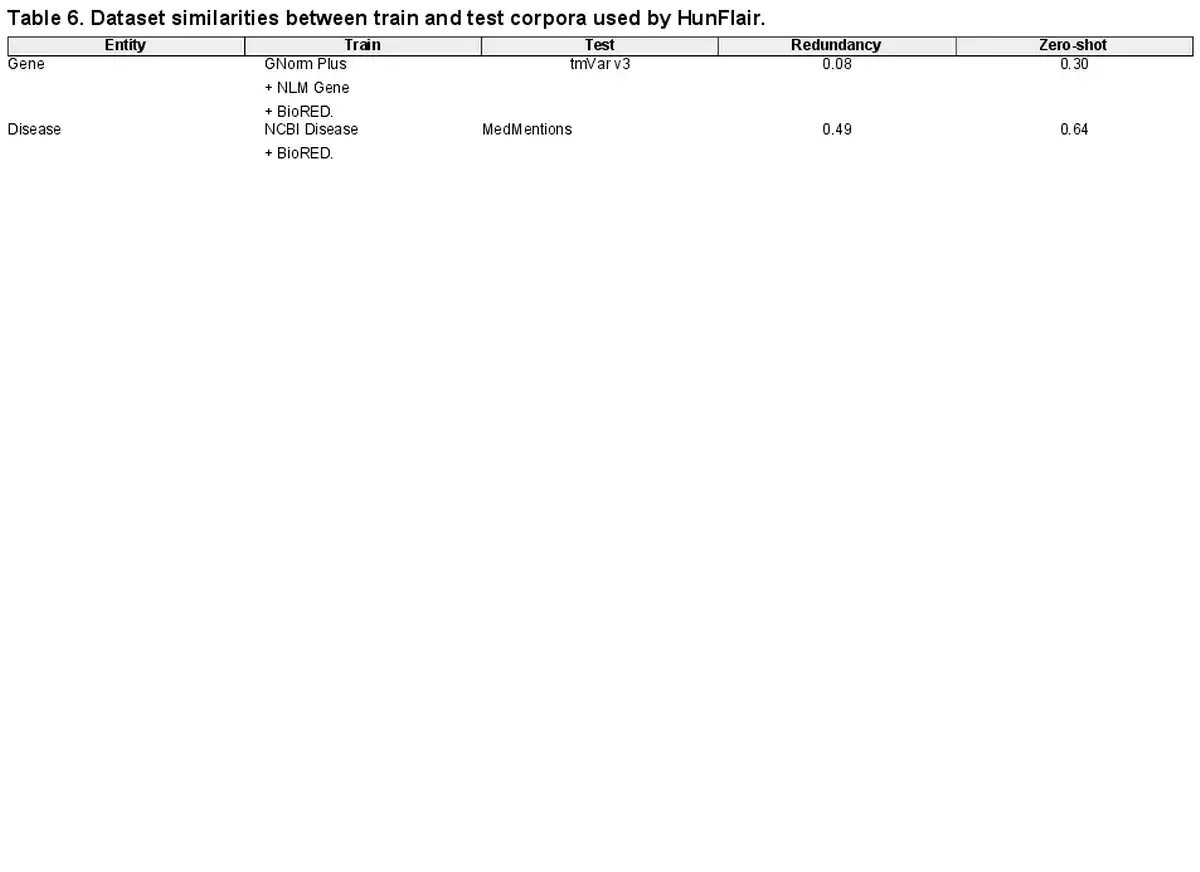
In addition to entity distribution biases in single corpora, the entities seen during training influence the tools’ performance. We analyze the overlaps of occurring entities in the training and (cross-corpus) test corpora to get insights into this factor. To quantify the overlaps, we rely on the redundancy and zero-shot values introduced by . The former measures the size of the intersection between unique train and test concepts divided by the total number of unique train concepts. The latter represents the ratio of unique test concepts not occurring in the train set (A redundancy score close to zero and a zero-shot score close to one indicate highly different train and test datasets.). We compute both scores for the gene and disease components of HunFlair2. The results of our analysis can be found in Table 6. For training HunFlair2’s gene recognition, GNormPlus, NLM Gene, and BioRED are used. Even though the redundancy between the train sets and the test dataset (i.e. tmvar v3) is low (0.08), the reported cross-corpus performance reaches a compelling F1-score of 76.75%. Concerning zero-shot instances, a value of 0.30 indicates that most genes have already been seen in the training dataset, making it easier for HunFlair2 to detect them. In the case of diseases, HunFlair2 was trained on NCBI Disease and BioRED (Note, we exclude SCAI diseases from this analysis as it includes no KB identifiers in its annotations.). In this scenario, we observe stark performance drops in our cross-corpus evaluation using MedMentions as test corpus (see Table 3). Although the redundancy between train and test corpora is much higher for diseases than for genes, the zero-shot ratio increases strongly, making it much harder for the extraction models to memorize already-seen entities.
4.3 NER performance
We examined the performance of the NER step separately to determine how much influence each step of the BTM pipeline has exactly on the overall performance and how much of the errors can be attributed to error propagation from the NER step. To this end, we compared the NER+NEN results to two “NER only” settings in Fig. 2. In the strict setting, detected entities that differ at most one character are still counted as true positives. In the lenient setting, detected entities that differ by at most one character and/or are a superstring or substring of a ground truth entity are counted as true positives.
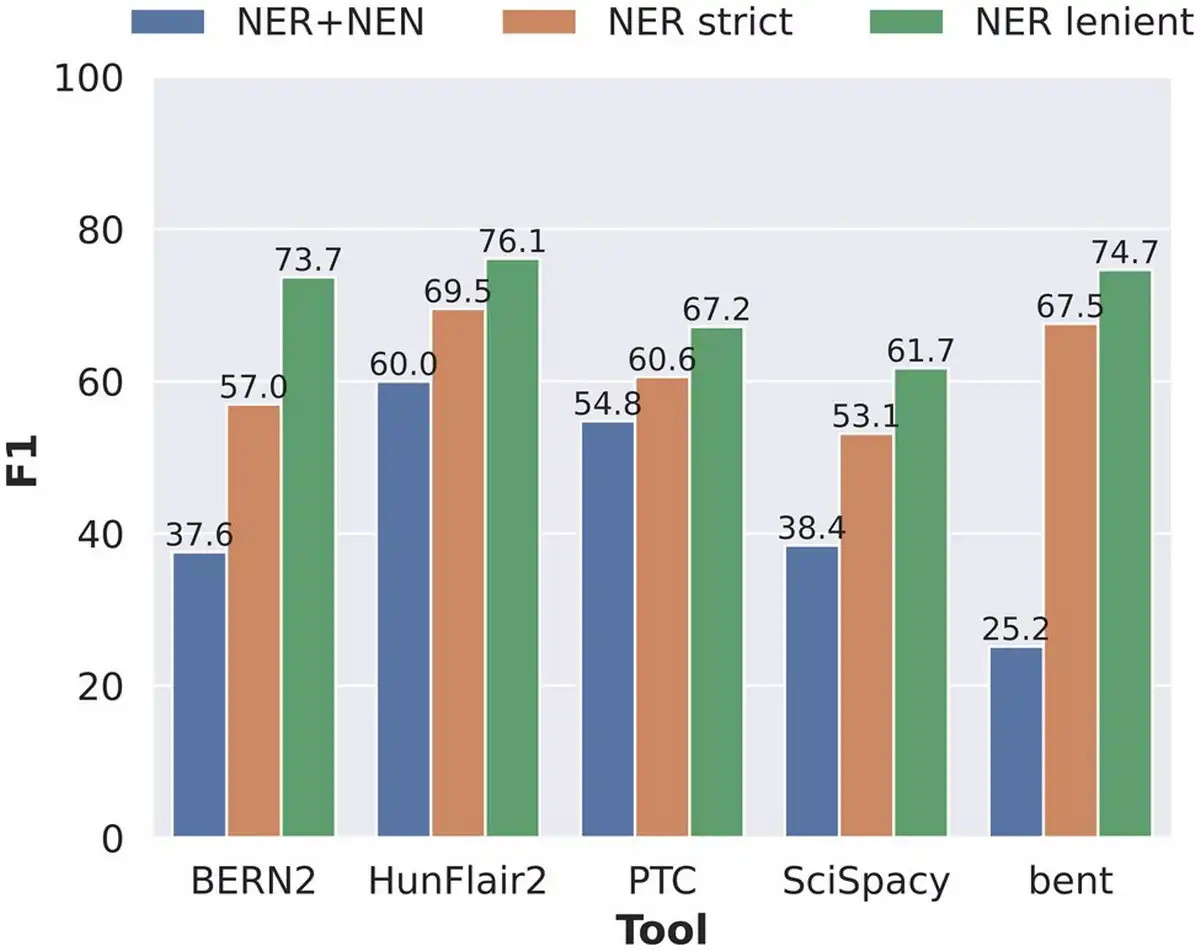
Figure 2
Performance comparison of the five tools concerning end-to-end NER+NEN, NER strict, and NER lenient evaluation settings, where each prediction is counted as a true positive if it is either a substring or a superstring of the gold standard entity mention.
HunFlair2 and PTC showed the most consistent performances across the three settings, indicating relatively robust performances for both the NER and NEN steps. The other three tools show much larger discrepancies between NER performances and joint NER+NEN results, indicating weaknesses in the normalization components. The largest drop between NER and joint NER+NEN is found in bent where performance in NER strict comes only second to HunFlair2 by a gap of 2.0 pp. When measuring NER+NEN, the F1-score then drops down to 25.2%. BERN2 is the only tool that shows significant discrepancy from NER lenient to NER strict evaluation, with the F1-score decreasing by 16.7 pp from 73.7% to 57.0%. A closer inspection of the BERN2 predictions reveals that the performance differences mostly stem from the handling of the token “gene” in gene entities. When the term “gene” immediately follows after a gene mention, e.g. in “AKT-1 gene,” BERN2 often annotates the term “gene” as part of its prediction, whereas the gold standard corpus does not. A detailed overview of NER performances split by corpus and entity types is given in Supplementary Data E2.
4.4 Reference ontologies
Creators of annotated corpora must decide, for each entity type, which ontology to use as the target for the normalization step (i.e. for NEN). Often, the entity annotation is already defined by a chosen ontology to have a clear definition of what to annotate and what not, i.e. already during NER. Furthermore, developers of NEN tools decide on which corpora they use for training, which implicitly also is a decision on which ontologies they can map to. To compare tools on corpora, which were designed for different ontologies for a given entity type, some form of ontology mapping has to be applied. Research in this field is rich () and often also addresses the issue of properly scoring hypernyms and hyponyms, i.e. cases where normalization yields a concept ID that is a generalization or specialization of the annotated concept ID (, ).
In this work, we restricted our evaluation to mappings readily provided with an ontology, for instance, the MeSH mappings for UMLS terms defined within UMLS, irrespective of their quality or coverage. This ensures that our results can be compared easily to past and future NEN evaluations with these ontologies, which would not be the case when custom-computed mappings are introduced. However, the applied mapping strategy introduces a bias toward specific systems. For example, it favors tools that predict coarse-grained MESH concepts instead of ones adhering to more fine-granular UMLS concepts. To account for this situation, we skip all predictions that exactly match nonmappable entities in our evaluation. To gain further insight into the impact of the mapping strategy, we computed the number of nonmappable entities mentioned in MedMentions to quantify this issue. We found that only 55.1% of the 35 014 diseases and 50.5% of the 38 037 chemical mentions could be mapped to MESH, limiting our evaluation. We list the 50 most frequent nonmappable entities, representing 30.4%/49.7% of all nonmappable disease/chemical mentions, in Supplementary Data G. The analysis shows that the top entities refer to rather general concepts such as pharmacologic substance (C1254351), proteins (C0033684), finding (C0243095), or diagnosis (C0011900). These investigations highlight that further research is strongly needed to harmonize existing and create additional NEN datasets, enabling a more robust assessment.
5 Conclusion
In this work, we reviewed 28 recent tools designed for extracting biomedical named entities from unstructured text regarding their maturity and ease of usage for downstream applications. We selected five tools, namely BERN2, bent, HunFlair2, PTC, and SciSpacy, for a detailed examination and assessed their performance on three different corpora, encompassing four types of entities, following a cross-corpus approach. Our experiments highlight that the performance of the tools varies considerably across corpora and entity types. Additionally, we found strong performance drops compared to the published in-corpus results. In-depth prediction analyses revealed that the tools demonstrate strong performance when identifying highly researched entities; however, they face challenges in accurately identifying concepts that rarely occur in the literature. In conclusion, our results illustrate that further research is needed on the generalization capabilities of named entity extraction tools to facilitate their seamless application to diverse biomedical subdomains and text types. In addition, our study highlights the crucial need to create additional NEN datasets and harmonize existing ones to foster a more effective evaluation of the available tools.
Acknowledgements
We thank the two anonymous reviewers for their constructive feedback.
References
- Arighi C, Hirschman L, Lemberger T et al Bio-ID track overview. In: BioCreative VI Challenge Evaluation Workshop, Vol. 482, Bethesda, Maryland USA: BioCreative VI Committees, 2017, 376.
- Bodenreider O. The Unified Medical Language System (UMLS): integrating biomedical terminology. Nucleic Acids Res2004;32:D267–70.
- Brown GR, Hem V, Katz KS et al Gene: a gene-centered information resource at NCBI. Nucleic Acids Res2015;43:D36–42.
- Cho H, Choi W, Lee H. A method for named entity normalization in biomedical articles: application to diseases and plants. BMC Bioinformatics2017;18:451–12.
- Collier N, Kim J-D. Introduction to the bio-entity recognition task at JNLPBA. In: International Joint Workshop on Natural Language Processing in Biomedicine and Its Applications, Geneva, Switzerland: COLING, 2004, 73–8.
- Davis AP, Wiegers TC, Johnson RJ et al Comparative Toxicogenomics Database (CTD): update 2023. Nucleic Acids Res2023;51:D1257–62.
- Euzenat J, Shvaiko P. Ontology Matching. Vol. 18, Berlin, Germany: Springer Nature, 2013.
- Ferré A, Langlais P. An analysis of entity normalization evaluation biases in specialized domains. BMC Bioinformatics2023;24:227.
- French E, McInnes BT. An overview of biomedical entity linking throughout the years. J Biomed Inform2022;137:104252.
- Fries J, Weber L, Seelam N et al BigBIO: a framework for data-centric biomedical natural language processing. Adv Neural Inf Process Syst2022;35:25792–806.
- Galea D, Laponogov I, Veselkov K. Exploiting and assessing multi-source data for supervised biomedical named entity recognition. Bioinformatics2018;34:2474–82.
- Garda S, Weber-Genzel L, Martin R et al BELB: a biomedical entity linking benchmark. Bioinformatics2023;39:btad698.
- Gerner M, Nenadic G, Bergman CM. LINNAEUS: a species name identification system for biomedical literature. BMC Bioinformatics2010;11:85.
- Giorgi JM, Bader GD. Towards reliable named entity recognition in the biomedical domain. Bioinformatics2020;36:280–6.
- Groth P, Weiss B, Pohlenz H-D et al Mining phenotypes for gene function prediction. BMC Bioinformatics2008;9:136.
- Gurulingappa H, Klinger R, Hofmann-Apitius M et al An empirical evaluation of resources for the identification of diseases and adverse effects in biomedical literature. In: 2nd Workshop on Building and Evaluating Resources for Biomedical Text Mining, Valletta, Malta: European Language Resources Association (ELRA), 2010, 15–22.
- Islamaj R, Leaman R, Kim S et al NLM-Chem, a new resource for chemical entity recognition in PubMed full text literature. Sci Data2021a;8:91.
- Islamaj R, Wei C-H, Cissel D et al NLM-Gene, a richly annotated gold standard dataset for gene entities that addresses ambiguity and multi-species gene recognition. J Biomed Inform2021b;118:103779.
- Keloth VK, Hu Y, Xie Q et al Advancing entity recognition in biomedicine via instruction tuning of large language models. Bioinformatics2024;40:btae163.
- Kolárik C, Klinger R, Friedrich CM et al Chemical names: terminological resources and corpora annotation. In: Workshop on Building and Evaluating Resources for Biomedical Text Mining, Vol. 36, European Language Resources Association: Marrakech, Morocco, 2008.
- Kosmopoulos A, Partalas I, Gaussier E et al Evaluation measures for hierarchical classification: a unified view and novel approaches. Data Min Knowl Disc2015;29:820–65.
- Leaman R, Lu Z. TaggerOne: joint named entity recognition and normalization with semi-Markov models. Bioinformatics2016;32:2839–46.
- Leaman R, Islamaj R, Adams V et al Chemical identification and indexing in full-text articles: an overview of the NLM-Chem track at BioCreative VII. Database2023;2023:baad005.
- Liu F, Shareghi E, Meng Z et al Self-alignment pretraining for biomedical entity representations. In: Conference of the North American Chapter of the Association for Computational Linguistics, Online: Association for Computational Linguistics, 2021, 4228–38. https://aclanthology.org/2021.naacl-main.334
- Lord PW, Stevens RD, Brass A et al Investigating semantic similarity measures across the gene ontology: the relationship between sequence and annotation. Bioinformatics2003;19:1275–83.
- Luo L, Lai P-T, Wei C-H et al BioRED: a rich biomedical relation extraction dataset. Brief Bioinform2022;23:bbac282.
- Luo L, Wei C-H, Lai P-T et al AIONER: all-in-one scheme-based biomedical named entity recognition using deep learning. Bioinformatics2023;39:btad310.
- Mohan S, Li D. MedMentions: a large biomedical corpus annotated with UMLS concepts. In: Proceedings of the 2019 Conference on Automated Knowledge Base Construction, Amherst, MA, USA, 2019.
- Morgan AA, Lu Z, Wang X et al Overview of BioCreative II gene normalization. Genome Biol2008;9:S3.
- Mujeen S, Minbyul J, Yonghwa C et al BERN2: an advanced neural biomedical named entity recognition and normalization tool. Bioinformatics2022;38:4837–9.
- Neumann M, King D, Beltagy I et al In: Demner-Fushman D, Cohen KB, Ananiadou S et al. (eds), Proceedings of the 18th BioNLP Workshop and Shared Task, Florence, Italy: Association for Computational Linguistics, 2019, 319--327, https://aclanthology.org/W19-5034
- Pafilis E, Frankild SP, Fanini L et al The species and organisms resources for fast and accurate identification of taxonomic names in text. PLoS One2013;8:e65390.
- Pyysalo S, Ohta T, Ananiadou S. Overview of the cancer genetics (CG) task of BioNLP shared task 2013. In Proceedings of the BioNLP Shared Task 2013 Workshop, Sofia, Bulgaria: Association for Computational Linguistics, 2013, 58–66.
- Ruas P, Lamurias A, Couto FM. Linking chemical and disease entities to ontologies by integrating PageRank with extracted relations from literature. J Cheminform2020;12:57.
- Ruas P, Sousa DF, Neves A et al LASIGE and UNICAGE solution to the NASA LitCoin NLP competition. arXiv, arXiv:2308.05609, 2023, preprint: not peer reviewed.
- Sänger M, Leser U. Large-scale entity representation learning for biomedical relationship extraction. Bioinformatics2021;37:236–42.
- Scott F. The NCBI Taxonomy database. Nucleic Acids Res2012;40:D136–43.
- Song B, Li F, Liu Y et al Deep learning methods for biomedical named entity recognition: a survey and qualitative comparison. Brief Bioinform2021;22:bbab282.
- Su Y, Wang M, Wang P et al Deep learning joint models for extracting entities and relations in biomedical: a survey and comparison. Brief Bioinform2022;23:bbac342.
- Sung M, Jeon H, Lee J et al Biomedical entity representations with synonym marginalization. In: Annual Meeting of the Association for Computational Linguistics, Online: Association for Computational Linguistics, 2020, 3641–50. https://aclanthology.org/2020.acl-main.335
- Wang X, Yang C, Guan R. A comparative study for biomedical named entity recognition. Int J Mach Learn Cyber2018;9:373–82.
- Wang XD, Weber L, Leser U. Biomedical event extraction as multi-turn question answering. In: International Workshop on Health Text Mining and Information Analysis, Online: Association for Computational Linguistics, 2020, 88–96. https://aclanthology.org/2020.louhi-1.10
- Weber L, Thobe K, Migueles Lozano OA et al PEDL: extracting protein–protein associations using deep language models and distant supervision. Bioinformatics2020;36:i490–8.
- Weber L, Sänger M, Münchmeyer J et al HunFlair: an easy-to-use tool for state-of-the-art biomedical named entity recognition. Bioinformatics2021;37:2792–4.
- Weber L, Sänger M, Garda S et al Chemical–protein relation extraction with ensembles of carefully tuned pretrained language models. Database2022;2022:baac098.
- Wei C-H, Kao H-Y. Cross-species gene normalization by species inference. BMC Bioinformatics2011;12:S5.
- Wei C-H, Kao H-Y, Lu Z. GNormPlus: an integrative approach for tagging genes, gene families, and protein domains. Biomed Res Int2015;2015:e918710.
- Wei C-H, Allot A, Leaman R et al PubTator Central: automated concept annotation for biomedical full text articles. Nucleic Acids Res2019;47:W587–93.
- Wei C-H, Allot A, Riehle K et al tmVar 3.0: an improved variant concept recognition and normalization tool. Bioinformatics2022;38:4449–51.
- Yasunaga M, Leskovec J, Liang P. LinkBERT: pretraining language models with document links. In: Muresan S, Nakov P, Villavicencio A (eds.), Annual Meeting of the Association for Computational Linguistics, Dublin, Ireland: Association for Computational Linguistics, 2022, 8003–16.
- Zhang Y, Zhang Y, Qi P et al Biomedical and clinical English model packages for the Stanza Python NLP library. J Am Med Inform Assoc2021;28:1892–9.